Are you venturing into the realm of machine learning and seeking to understand how algorithms categorize data? You’ve come to the right place. Machine learning classification techniques are the backbone of many intelligent systems, enabling machines to learn from data and make informed predictions about the categories new data belongs to. This article delves into the essential world of classification in machine learning, exploring the top algorithms used for this purpose.
Understanding classification algorithms is crucial for anyone working with data, from aspiring data scientists to seasoned professionals. These techniques are employed across diverse fields, helping to solve real-world problems by automating decision-making and pattern recognition. Whether you’re interested in spam detection, medical diagnosis, or image recognition, classification algorithms are the key.
In this guide, we will explore the top machine learning classification algorithms, dissecting their methodologies, advantages, and disadvantages. Our aim is to equip you with the knowledge to understand and apply these powerful tools effectively.
Delving into Classification in Machine Learning
Classification in machine learning is a supervised learning approach where the primary goal is to predict the discrete class label of a new data point based on its features. Think of it as teaching a machine to sort items into predefined boxes. In essence, a classification algorithm learns from a labeled dataset, where each data point is already assigned to a specific category. This learning process enables the algorithm to then classify new, unseen data points into one of these learned categories.
The process begins with training a model on a dataset where each instance or observation is meticulously labeled with its corresponding class. This labeled data acts as the algorithm’s learning material. Once trained, the model can then be used to predict the class labels for new, unlabeled instances. This predictive capability is what makes classification algorithms so valuable in countless applications.
Top Machine Learning Classification Algorithms: An Overview
Classification algorithms are the workhorses of machine learning when it comes to organizing and interpreting complex datasets. These algorithms are fundamental for tasks that require categorizing data into distinct classes or labels, automating decision-making processes, and identifying underlying patterns. A classic example of their utility is in email spam detection. By analyzing email content, classification algorithms can quickly learn to recognize patterns indicative of spam, enabling real-time judgments and significantly enhancing email security.
Here’s a list of some of the most effective and widely-used machine learning classification algorithms:
- Logistic Regression
- Decision Tree
- Random Forest
- Support Vector Machine (SVM)
- Naive Bayes
- K-Nearest Neighbors (KNN)
Let’s explore each of these algorithms in detail to understand their unique characteristics and applications.
1. Logistic Regression: Mastering Binary Classification
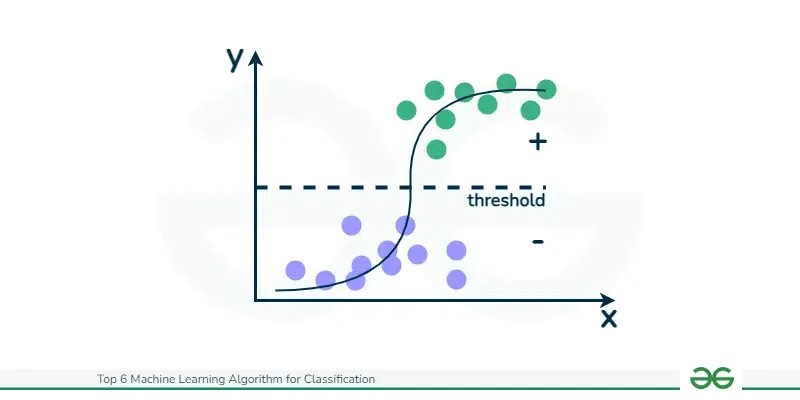
Logistic regression is a cornerstone classification algorithm primarily used for estimating the probability of a discrete outcome, most commonly in binary scenarios. It excels in situations where the outcome can be one of two possibilities, such as “yes” or “no,” “0” or “1,” or “true” or “false.” The algorithm predicts the probability that a given data instance belongs to a particular class, making it invaluable for binary classification problems like spam detection (spam or not spam) or disease diagnosis (disease present or absent).
The beauty of logistic regression lies in its use of the logistic function (also known as the sigmoid function). This function ensures that the output is always constrained between 0 and 1, perfectly representing probabilities. Its simplicity, interpretability, and efficiency make it a favorite across various domains. Logistic regression is particularly effective when the relationship between the features and the probability of the event is linear.
Key Features of Logistic Regression
-
Binary Outcome Focus: Logistic regression is specifically designed for scenarios where the dependent variable is binary, meaning it has only two possible outcomes. This makes it ideal for yes/no, true/false, or 0/1 type predictions.
-
Probabilistic Output: It doesn’t just classify; it predicts the probability of an event occurring. By fitting data to a logistic function, it outputs a value between 0 and 1, representing the likelihood that an input belongs to the ‘1’ category.
-
Odds Ratio Estimation: Logistic regression is capable of estimating the odds ratio when dealing with multiple explanatory variables. This is crucial for understanding the strength and direction of the association between independent variables and the binary dependent variable.
-
Logit Function Foundation: At its core, logistic regression uses the logit function (or logistic function) to model the data. This S-shaped curve elegantly maps any real-valued number into a probability value between 0 and 1, making it perfect for classification tasks.
2. Decision Trees: Intuitive and Interpretable Classifiers
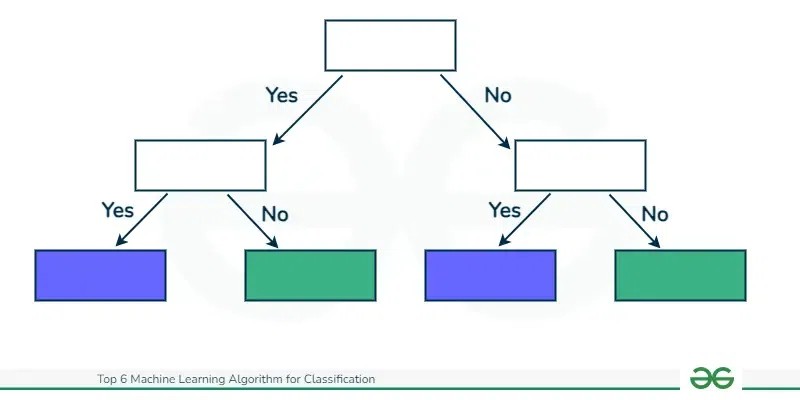
Decision Trees stand out as versatile and remarkably interpretable techniques for both classification and regression tasks. They operate by recursively partitioning the dataset into subsets based on feature values, creating a tree-like structure. Each internal node in the tree represents a decision based on a feature, each branch represents the outcome of that decision, and each leaf node represents a class label or a prediction.
Decision trees are prized for their ease of understanding and visual representation, making them invaluable tools for decision-making processes. Their structure directly mirrors human decision-making logic, enhancing interpretability. However, decision trees can be prone to overfitting, especially with complex datasets. Techniques like pruning are often employed to improve their generalization capabilities and prevent overfitting.
Key Features of Decision Trees
-
Tree-Like Structure: Decision Trees are characterized by their flowchart-like structure. Each internal node poses a “test” on an attribute, branches signify the test outcomes, and leaf nodes represent the final class label or decision. The paths from the root to the leaves essentially encode classification rules.
-
Simplicity and Interpretability: One of the most significant advantages of Decision Trees is their inherent simplicity and ease of interpretation. They can be readily visualized, which simplifies understanding how decisions are made and explaining the rationale behind predictions to stakeholders.
-
Versatility Across Data Types: Decision Trees are highly versatile, capable of handling both numerical and categorical data. Furthermore, they can be applied to both regression and classification problems, making them adaptable to a wide array of data types and analytical challenges.
-
Feature Importance Indication: Decision Trees naturally perform feature selection during the tree building process. They provide intrinsic insights into feature importance, highlighting the most influential variables for making predictions. Features closer to the root of the tree are deemed more important, offering a straightforward way to identify critical variables.
3. Random Forest: Enhancing Accuracy Through Ensemble Learning
Random Forests are a powerful ensemble learning technique that leverages the collective intelligence of multiple decision trees to boost predictive accuracy and effectively control overfitting. By aggregating the predictions from numerous trees, Random Forests significantly enhance the decision-making process, making them remarkably robust against noise and bias in the data.
The core idea behind Random Forests is to build a multitude of decision trees during training and then output the class that is the mode of the classes (for classification) or the mean prediction (for regression) of the individual trees. Randomness is introduced in two key ways: by using bootstrap sampling (randomly selecting data points with replacement) and by random feature selection (considering only a subset of features at each node split). This randomness ensures diversity among the trees, which is crucial for the ensemble’s performance. Random Forests are particularly adept at handling high-dimensional data, providing robust feature importance measures, and exhibiting strong resistance to overfitting. Their versatility makes them applicable to both classification and regression problems across diverse domains.
Key Features of Random Forests
-
Ensemble Method Approach: Random Forest employs the ensemble learning technique, where multiple learners (decision trees in this case) are trained to solve the same problem. Their predictions are then combined to achieve superior overall performance. This ensemble approach is the key to improving both accuracy and robustness compared to single decision trees.
-
Handles Diverse Data Types: Random Forests are capable of processing both categorical and continuous input and output variables. This flexibility makes them suitable for various types of data without requiring extensive preprocessing for different variable types.
-
Overfitting Reduction: By averaging the predictions of multiple trees, Random Forests significantly reduce the risk of overfitting. This aggregation stabilizes the model and enhances its ability to generalize to unseen data, making it more reliable for real-world applications.
-
Robust to Missing Values: Random Forests exhibit inherent capabilities to handle missing values in datasets. When encountering a missing value for a variable, the algorithm can impute it by using the median (for numerical variables) or the mode (for categorical variables) of the samples that reach the node where the missing value is present. This imputation mechanism allows the algorithm to maintain performance even with incomplete datasets.
4. Support Vector Machines (SVM): Maximizing Margins for Optimal Classification
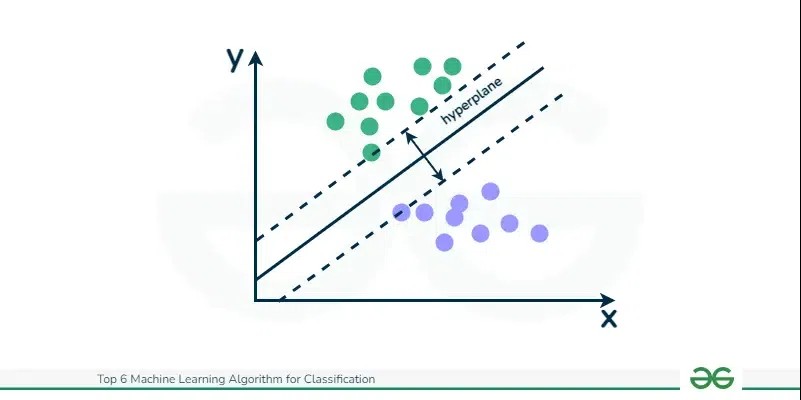
Support Vector Machines (SVM) are a powerful class of algorithms effective for both classification and regression. SVMs operate on the principle of finding an optimal hyperplane that distinctly separates different classes in the feature space while maximizing the margin. The margin is defined as the distance between the hyperplane and the nearest data points from each class, known as support vectors. SVM algorithms are particularly well-suited for high-dimensional spaces and are adept at handling non-linear feature interactions through the use of kernel techniques. They are recognized as robust classification algorithms known for their accuracy, especially in scenarios with high-dimensional data.
SVMs are inherently robust against overfitting and tend to generalize well to new datasets. Their applications are widespread, including image recognition, text classification, and bioinformatics, particularly in areas where high precision is paramount. The ability to handle complex datasets and deliver accurate classifications makes SVMs a go-to choice in numerous advanced applications.
Key Features of Support Vector Machines
-
Margin Maximization Principle: SVM’s core objective is to identify the hyperplane that best separates classes in the feature space while simultaneously maximizing the margin. This margin maximization is crucial because a larger margin typically leads to better generalization performance on unseen data.
-
Support Vectors as Key Elements: The algorithm’s name itself is derived from “support vectors.” These are the data points closest to the decision boundary (hyperplane) and are critical for defining the hyperplane’s position and orientation. SVMs are memory-efficient because only these support vectors, a subset of the training data, are needed to define the classification model.
-
Kernel Trick for Non-Linearity: One of the most powerful features of SVMs is the “kernel trick.” This technique allows SVMs to operate in high-dimensional feature spaces without explicitly calculating the coordinates of the data in that space. By using kernel functions (like linear, polynomial, radial basis function (RBF), sigmoid), SVMs can efficiently handle non-linearly separable data by transforming it into a higher-dimensional space where linear separation becomes feasible.
-
Versatility Through Kernel Choice: SVMs are remarkably versatile due to the variety of kernel functions available (linear, polynomial, RBF, sigmoid, etc.). The choice of kernel allows SVMs to be adapted to solve a broad spectrum of problems, including those with complex, non-linear decision boundaries. This adaptability makes SVMs suitable for diverse types of datasets and problem complexities.
5. Naive Bayes: Simple and Efficient Probabilistic Classifier
Naive Bayes classifiers are probabilistic classification algorithms rooted in Bayes’ theorem. They are particularly effective for text categorization and spam filtering. Naive Bayes algorithms are known for their simplicity and their “naive” assumption of feature independence. Despite this simplification, Naive Bayes often performs surprisingly well in practice, especially in high-dimensional settings. The algorithm uses conditional probabilities of features to compute the likelihood of an instance belonging to a particular class. Its efficiency and effectiveness make Naive Bayes a popular choice for tasks involving large datasets and numerous features.
The foundation of Naive Bayes lies in Bayes’ theorem, which describes the probability of an event based on prior knowledge of conditions that might be related to the event. Naive Bayes classifiers operate under the assumption that the presence (or absence) of a specific feature of a class is independent of the presence (or absence) of any other feature, given the class variable. This assumption, while often not entirely true in real-world data, simplifies computations significantly and contributes to the algorithm’s speed and robustness.
Key Features of Naive Bayes
-
Probabilistic Foundation Based on Bayes’ Theorem: Naive Bayes classifiers are fundamentally probabilistic, leveraging Bayes’ theorem to calculate the probability of a given instance belonging to each possible class. Decisions are then made based on these posterior probabilities, selecting the class with the highest probability.
-
Feature Independence Assumption: The algorithm’s “naive” aspect comes from its assumption that the features used to predict the class are conditionally independent of each other, given the class. While this assumption is often violated in real-world scenarios, it greatly simplifies the model and, surprisingly, often leads to effective classification performance, especially in text-related tasks.
-
Computational Efficiency: Naive Bayes classifiers are exceptionally efficient in terms of computation and memory usage. They require a relatively small amount of training data to accurately estimate the parameters (probabilities) necessary for classification. This efficiency makes them well-suited for large datasets and real-time applications.
-
Ease of Implementation and Interpretation: The algorithm is straightforward to implement and relatively easy to understand, making it accessible even for those new to machine learning. It provides a solid and efficient starting point for many classification tasks, especially when dealing with categorical data and text classification.
6. K-Nearest Neighbors (KNN): Classification by Proximity
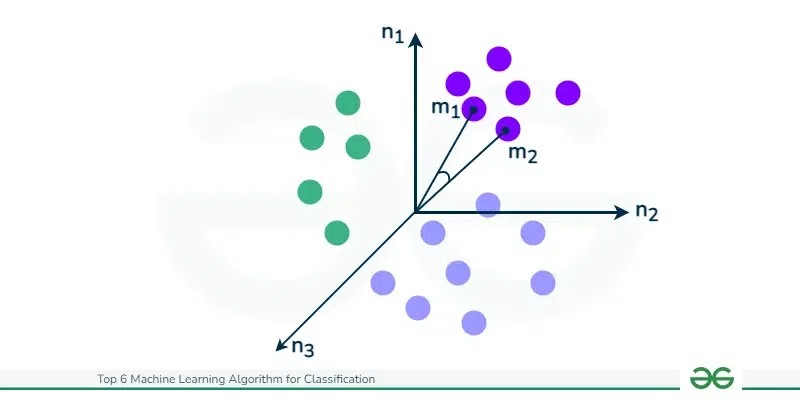
K-Nearest Neighbors (KNN) is an algorithm celebrated for its simplicity and adaptability in both classification and regression tasks. KNN performs classification by assigning a class to a new data point based on the majority class among its k-nearest neighbors in the feature space. Being a non-parametric algorithm, KNN makes no assumptions about the underlying data distribution, offering flexibility in various scenarios. It particularly excels with datasets that have complex, irregular decision boundaries and is effective in a wide range of applications.
K-Nearest Neighbors (KNN) falls under the category of instance-based or lazy learning algorithms. Unlike eager learners that build a model during the training phase, KNN defers computation until prediction time. It classifies new instances based on a similarity measure, typically using distance functions (e.g., Euclidean distance, Manhattan distance). KNN’s simplicity and effectiveness in handling non-linear data contribute to its widespread use in recommendation systems, anomaly detection, and pattern recognition tasks.
Key Features of K-Nearest Neighbors (KNN)
-
Instance-Based Learning Approach: KNN is an instance-based or lazy learning algorithm, meaning it doesn’t explicitly learn a discriminative model from the training data. Instead, it memorizes the training dataset and uses it directly at prediction time to classify new instances.
-
Simplicity and Ease of Implementation: One of KNN’s primary advantages is its simplicity. The algorithm is conceptually straightforward, easy to understand, and requires minimal implementation effort. It doesn’t involve a training phase in the traditional sense, which simplifies the development process.
-
Non-Parametric Nature: KNN is a non-parametric method, which means it makes no assumptions about the underlying distribution of the data. This characteristic provides significant flexibility, allowing KNN to be applied effectively in situations where the data distribution is unknown or deviates from standard assumptions.
-
Flexibility in Distance Metric Choice: The performance of KNN can be significantly influenced by the choice of distance metric used to determine the “nearest neighbors.” Common distance metrics include Euclidean, Manhattan, and Minkowski distances. This flexibility allows for customization based on the specific characteristics of the dataset and the problem, enabling optimization for different types of data structures and relationships.
Comparison of Top Machine Learning Classification Algorithms
To better understand the nuances and trade-offs between these algorithms, let’s compare them across several key features:
Comparison Table: Top 6 Machine Learning Classification Algorithms
| Feature | Decision Tree | Random Forest | Naive Bayes | Support Vector Machines (SVM) | K-Nearest Neighbors (KNN) |
|---|---|---|---|---|---|
| Type | Tree-based model | Ensemble Learning (Bagging) | Probabilistic model | Margin-based model | Instance-based model |
| Output | Categorical or Continuous | Categorical or Continuous | Categorical | Categorical or Continuous | Categorical |
| Assumptions | Minimal | Similar to Decision Tree, improved accuracy | Assumes feature independence | Data is separable in high-dimensional space | Similar instances lead to similar outcomes |
| Strengths | Simple, interpretable, versatile | Handles overfitting, good for large datasets | Efficient, works with high-dimensional data | Effective in high-dimensional spaces, versatile | Simple, effective for small datasets |
| Weaknesses | Prone to overfitting | More complex, computationally intensive | Simplistic assumption limits performance | Memory intensive, interpretability | Sensitive to data scale, irrelevant features |
| Use Cases | Feature importance, diverse tasks | Large datasets, robust classification | Text classification, spam filtering | Image recognition, text categorization | Recommendation systems, anomaly detection |
| Training Time | Fast | Slower than Decision Tree | Very fast | Medium to high (kernel dependent) | Fast for small datasets, slow for large |
| Interpretability | High | Medium (ensemble nature) | High (simple probabilistic model) | Low (complex transformations) | High |
Choosing the Right Algorithm for Your Data
Selecting the most appropriate machine learning algorithm for classification is contingent upon careful consideration of both the problem you are trying to solve and the characteristics of your dataset. Each algorithm possesses unique strengths and is best suited for different types of data and problem scenarios.
-
Decision Trees and Random Forests are excellent starting points due to their versatility and ease of implementation. They are particularly useful when interpretability is important and for datasets with mixed data types.
-
Logistic Regression is the go-to algorithm for binary classification problems, especially when you need to understand the probability of outcomes.
-
Support Vector Machines shine when dealing with high-dimensional data and complex decision boundaries. They are a strong choice when accuracy is paramount, and you have the computational resources.
-
K-Nearest Neighbors is ideal for scenarios where simplicity is key, and you are working with smaller datasets. It’s also effective when the decision boundary is irregular and non-linear.
-
For very complex problems, especially those involving unstructured data like images or text, and for very large datasets, consider more advanced techniques such as Deep Learning models. Convolutional Neural Networks (CNNs) are powerful for image classification, and Recurrent Neural Networks (RNNs) excel with sequence data. While more complex to implement and train, they can offer superior performance in challenging problem spaces.
Conclusion: Mastering Classification Techniques
Classification techniques in machine learning have revolutionized how we analyze and interpret data. This article has explored six of the top machine learning algorithms for classification: Decision Tree, Random Forest, Naive Bayes, Support Vector Machines, K-Nearest Neighbors. Each algorithm brings its own set of strengths and applications, making them valuable tools for tackling diverse categorization challenges.
By understanding the principles, advantages, and limitations of these algorithms, data scientists and practitioners are better equipped to address real-world classification problems effectively. The right choice of algorithm, tailored to the specific data and problem at hand, is crucial for achieving accurate and insightful results in machine learning classification tasks.
Top 6 Machine Learning Classification Algorithms – FAQ’s
What is the primary function of machine learning classification algorithms?
Machine learning classification algorithms are designed to autonomously identify patterns within datasets and make decisions by categorizing data into predefined classes or labels. These algorithms are instrumental in automating decision-making processes across various applications and significantly enhance pattern identification within complex datasets.
What distinguishes logistic regression from other classification techniques?
Logistic regression, despite its name, is fundamentally a classification algorithm that predicts the probability of class membership. It uniquely uses a logistic function (sigmoid function) to model probability, constraining the output between 0 and 1. This makes it particularly suitable for binary classification tasks where the outcome is binary (e.g., 0 or 1, yes or no).
What makes Naive Bayes an effective method for spam filtering and text classification?
Naive Bayes is a probabilistic classification algorithm based on Bayes’ theorem. Its effectiveness in spam filtering and text classification stems from its ability to use conditional probabilities of features to determine class membership. Despite its simplicity and the ‘naive’ assumption of feature independence, it often performs remarkably well, especially with high-dimensional text data.
What role does KNN play in both regression and classification tasks?
K-Nearest Neighbors (KNN) algorithm uses proximity to perform both regression and classification. In classification, KNN categorizes instances based on the majority class among its k-nearest neighbors. Its simplicity, non-parametric nature, and adaptability make it useful for a wide range of tasks, particularly where decision boundaries are complex and datasets are moderately sized.
How should one select the best machine learning algorithm for a specific problem?
Selecting the optimal machine learning algorithm necessitates a careful evaluation of the problem’s specifics and the dataset’s characteristics. Consider factors such as data dimensionality, linearity, interpretability requirements, and dataset size. For high-dimensional data, SVMs are effective; for mixed data types, decision trees and random forests are versatile; logistic regression is ideal for binary outcomes; and KNN is suitable for smaller datasets and non-linear boundaries. Experimenting with several algorithms and understanding the nuances of your problem will facilitate choosing the most effective solution.