A decision tree, in the context of machine learning, is a supervised learning algorithm used for both classification and regression tasks. It visually represents a series of decisions and their potential outcomes, resembling a flowchart or tree structure. This model predicts the value of a target variable by learning simple decision rules inferred from the data features. Let’s delve deeper into what constitutes a decision tree, how it functions, and its practical applications.
Components of a Decision Tree
A decision tree is composed of several key elements:
- Root Node: This is the starting point of the tree, representing the entire dataset or the initial question to be answered.
- Branches: These lines connect nodes, illustrating the flow of decisions based on different attribute values.
- Internal Nodes: Also known as decision nodes, these represent points where the data is split based on a specific feature. Each internal node corresponds to a test on an attribute, and each branch represents the outcome of that test.
- Leaf Nodes: These are the terminal points of the tree, representing the final outcome or prediction. Each leaf node assigns a class label (in classification) or a numerical value (in regression).
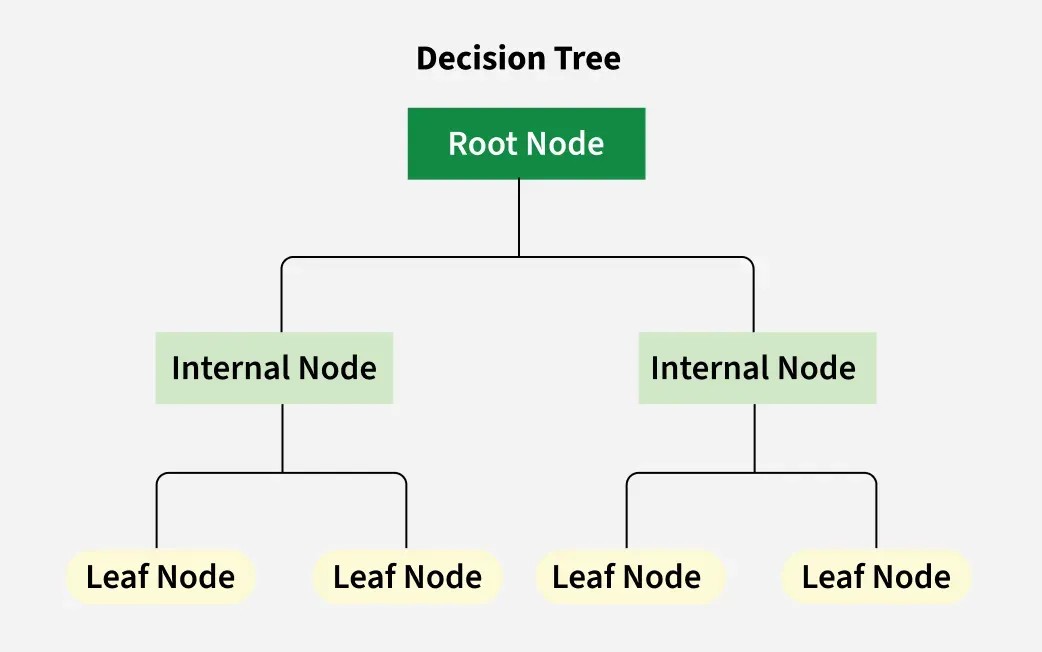 Decision Tree Structure
Decision Tree Structure
For instance, imagine deciding whether to play outdoor sports based on weather conditions. The root node might ask, “Is it raining?” Branches would then lead to “Yes” and “No.” Further decisions could be made based on temperature and wind speed, ultimately leading to a leaf node with the final decision: “Play” or “Don’t Play.”
Types of Decision Trees
Decision trees are primarily categorized into two types:
- Classification Trees: These are used when the target variable is categorical, meaning it belongs to distinct classes. For example, classifying emails as spam or not spam.
- Regression Trees: These are used when the target variable is continuous, representing a numerical value. For example, predicting the price of a house based on its features.
How Decision Trees Work
A decision tree learns from a labeled dataset, where each instance has a set of features and a corresponding target value. The algorithm aims to build a tree that accurately predicts the target value for new, unseen instances.
The process typically involves recursively partitioning the data based on the most informative features. At each node, the algorithm selects the feature that best separates the data into subsets that are more homogenous with respect to the target variable. Common splitting criteria include Gini impurity, information gain, and variance reduction. This process continues until a stopping criterion is met, such as a maximum depth or a minimum number of samples per leaf.
Advantages of Decision Trees
- Easy to Understand and Interpret: The visual nature of decision trees makes them easy to comprehend, even for non-technical users.
- Versatile: Applicable to both classification and regression problems.
- Requires Minimal Data Preprocessing: Decision trees are generally robust to outliers and missing values, and they don’t require feature scaling.
- Can Handle Non-linear Relationships: Capable of capturing complex, non-linear relationships between features and the target variable.
Disadvantages of Decision Trees
- Prone to Overfitting: Decision trees can easily become overly complex, memorizing the training data instead of learning generalizable patterns. Techniques like pruning and setting limits on tree depth can help mitigate this issue.
- Instability: Small changes in the data can lead to significant changes in the tree structure, making the model unstable. Ensemble methods like random forests can improve stability.
- Bias Towards Features with More Levels: Features with a larger number of distinct values tend to have a stronger influence on the tree structure.
Applications of Decision Trees
Decision trees find applications in various fields, including:
- Finance: Assessing credit risk, detecting fraudulent transactions, and making investment decisions.
- Healthcare: Diagnosing diseases, predicting patient outcomes, and personalizing treatment plans.
- Marketing: Customer segmentation, targeted advertising, and predicting customer churn.
- Operations: Optimizing resource allocation, predicting equipment failure, and improving supply chain efficiency.
Decision trees are a valuable tool in the machine learning arsenal, offering a balance between interpretability and predictive power. While they have limitations, various techniques can be employed to improve their performance and robustness.
