Feature selection in machine learning is a pivotal process, and at LEARNS.EDU.VN, we empower you to master it for enhanced model performance. This guide dives deep into feature selection, also known as attribute selection, explaining its methods, benefits, and how it streamlines machine learning workflows, ultimately improving predictive accuracy and model interpretability. Master dimensionality reduction, variable selection, and attribute extraction with us.
1. Understanding Feature Selection in Machine Learning
In the realm of machine learning, feature selection is the art and science of choosing the most relevant subset of features from your original dataset. Think of it as decluttering your data – eliminating the noise and focusing on the signals that truly matter. It’s a critical step toward building more effective and efficient predictive models. Feature selection techniques are crucial for data preprocessing.
1.1. Why is Feature Selection Important?
Imagine you’re trying to predict whether a customer will click on an ad. You have hundreds of data points, from age and location to browsing history and time of day. However, not all of these factors are equally important. Some might be irrelevant, redundant, or even misleading. Feature selection helps you:
- Improve Accuracy: By removing irrelevant features, you reduce the risk of overfitting, where your model learns the noise in the data rather than the underlying patterns. A more focused model generally translates to better predictions on new data.
- Reduce Complexity: Fewer features mean simpler models that are easier to understand and interpret. This is especially valuable in fields like medicine or finance, where explainability is paramount.
- Speed Up Training: Training models on fewer features requires less computational power and time. This is crucial when working with large datasets or complex models.
- Enhance Generalization: A model trained on relevant features is more likely to generalize well to unseen data. This means it will perform consistently even when faced with new and different scenarios.
1.2. The Core Objectives of Feature Selection
At its heart, feature selection aims to achieve the following:
- Identify the most informative features: Pinpointing the variables that have the strongest relationship with the target variable (the one you’re trying to predict).
- Eliminate irrelevant features: Removing features that have little or no impact on the target variable.
- Reduce redundancy: Addressing multicollinearity, where features are highly correlated with each other and provide overlapping information.
- Enhance model interpretability: Making the model easier to understand and explain to stakeholders.
1.3. Feature Selection vs. Dimensionality Reduction
It’s important to distinguish feature selection from dimensionality reduction techniques like Principal Component Analysis (PCA). While both aim to reduce the number of variables, they operate differently. Feature selection selects a subset of the original features, while dimensionality reduction transforms the original features into a new set of uncorrelated variables.
- Feature Selection: Keeps the original features, making the results easily interpretable.
- Dimensionality Reduction: Creates new, artificial features that may be harder to understand in the context of the original data.
2. Key Benefits of Feature Selection
Feature selection offers a multitude of benefits that can significantly improve the performance and usability of machine learning models. These advantages span accuracy, efficiency, interpretability, and generalization.
2.1. Improved Model Accuracy
By focusing on the most relevant features, we prevent the model from being distracted by noise or irrelevant data. This leads to a more accurate representation of the underlying patterns and relationships within the data.
2.2. Reduced Overfitting
Overfitting occurs when a model learns the training data too well, including its noise and outliers. This results in poor performance on new, unseen data. Feature selection helps mitigate overfitting by simplifying the model and reducing its sensitivity to irrelevant variations in the training data.
2.3. Faster Training Times
Training a model on a smaller set of features naturally takes less time and computational resources. This is particularly important when working with large datasets or complex models. Faster training times allow for more experimentation and iteration, leading to better model development.
2.4. Enhanced Model Interpretability
Simpler models with fewer features are easier to understand and explain. This is crucial in applications where transparency and explainability are essential, such as in healthcare or finance. Stakeholders can gain confidence in the model’s predictions when they understand the reasoning behind them.
2.5. Better Generalization
A model trained on relevant features is more likely to generalize well to unseen data. This means it will perform consistently even when faced with new and different scenarios. Feature selection helps create models that are robust and adaptable to real-world conditions.
2.6. Mitigation of the Curse of Dimensionality
The “curse of dimensionality” refers to the challenges that arise when working with high-dimensional data. As the number of features increases, the amount of data required to train a reliable model grows exponentially. Feature selection helps to alleviate this problem by reducing the dimensionality of the data, making it more manageable and improving model performance.
2.7. Cost Reduction
In some cases, the cost of acquiring or processing certain features can be significant. Feature selection can help identify and eliminate those costly features that provide little or no value to the model, resulting in significant cost savings.
2.8. Simplified Data Visualization
Working with a smaller number of features makes it easier to visualize the data and gain insights into the relationships between variables. This can be valuable for exploratory data analysis and for communicating findings to stakeholders.
3. Feature Selection Methods: A Detailed Overview
Feature selection methods can be broadly categorized into three main types: Filter methods, Wrapper methods, and Embedded methods. Each category has its own strengths, weaknesses, and underlying principles.
3.1. Filter Methods
Filter methods evaluate the relevance of features based on statistical measures and scores, without involving any specific machine learning algorithm. They act as a preprocessing step, filtering out irrelevant features before the model training begins.
- How They Work: Filter methods assess each feature independently with respect to the target variable. They rely on statistical tests like correlation, chi-squared, or information gain to rank features based on their relevance.
- Advantages:
- Computational Efficiency: Filter methods are generally very fast and computationally inexpensive, making them suitable for high-dimensional datasets.
- Independence from Algorithms: They are independent of the specific machine learning algorithm used, allowing for flexibility in model selection.
- Disadvantages:
- Ignores Feature Dependencies: Filter methods treat each feature in isolation, ignoring potential interactions or dependencies between features.
- Suboptimal Feature Subset: They may not always select the optimal feature subset for a particular model, as they don’t take the model’s performance into account.
3.1.1. Common Filter Method Techniques
- Information Gain: Measures the reduction in entropy (uncertainty) of the target variable when a particular feature is known. Higher information gain indicates a more relevant feature.
- Chi-squared Test: Used for categorical features to determine the independence between a feature and the target variable. A low p-value suggests that the feature is relevant.
- Fisher’s Score: A statistical measure that quantifies the separability of classes based on a feature’s values. Higher Fisher’s score indicates a better feature for classification.
- Correlation Coefficient: Measures the linear relationship between two continuous variables. High correlation (positive or negative) suggests a strong relationship.
- Variance Threshold: Removes features with low variance, as they are unlikely to contain much information.
- Mean Absolute Difference (MAD): Calculates the average absolute difference between each feature value and its mean. Features with higher MAD are considered more relevant.
- Dispersion Ratio: Measures the spread of a feature’s values relative to its mean. Higher dispersion ratio suggests a more informative feature.
3.2. Wrapper Methods
Wrapper methods evaluate feature subsets by training a specific machine learning model on each subset and assessing its performance. They search for the optimal feature subset that maximizes the model’s accuracy.
- How They Work: Wrapper methods use a search algorithm to explore different combinations of features. For each subset, they train a model and evaluate its performance using a validation set or cross-validation. The subset that yields the best performance is selected.
- Advantages:
- Optimized for Specific Model: Wrapper methods are tailored to a particular machine learning algorithm, resulting in a feature subset that is well-suited for that model.
- Captures Feature Dependencies: They can capture interactions and dependencies between features, leading to better model performance.
- Disadvantages:
- Computationally Expensive: Wrapper methods are generally more computationally expensive than filter methods, especially for large datasets.
- Risk of Overfitting: They can be prone to overfitting if the model is too complex or the validation set is not representative of the population.
3.2.1. Common Wrapper Method Techniques
- Forward Selection: Starts with an empty set of features and iteratively adds the feature that most improves the model’s performance.
- Backward Elimination: Starts with all features and iteratively removes the least significant feature until the desired performance is achieved.
- Recursive Feature Elimination (RFE): Recursively trains a model and removes the least important features based on their weights or coefficients.
3.3. Embedded Methods
Embedded methods perform feature selection as an integral part of the model training process. They combine the advantages of both filter and wrapper methods, offering a balance between computational efficiency and model-specific optimization.
- How They Work: Embedded methods incorporate feature selection directly into the model’s learning algorithm. The model automatically selects the most relevant features during training, based on criteria like regularization or feature importance.
- Advantages:
- Efficiency: Embedded methods are generally more efficient than wrapper methods, as they don’t require separate training and evaluation steps for each feature subset.
- Model-Specific Optimization: They are tailored to a specific machine learning algorithm, resulting in a feature subset that is well-suited for that model.
- Disadvantages:
- Limited Applicability: Embedded methods are specific to certain types of models, limiting their flexibility.
3.3.1. Common Embedded Method Techniques
- L1 Regularization (Lasso): Adds a penalty term to the model’s objective function that encourages sparsity in the feature weights. Features with zero weights are effectively removed.
- Decision Trees and Random Forests: These algorithms inherently perform feature selection by selecting the most important features for splitting nodes based on criteria like Gini impurity or information gain.
- Gradient Boosting: Similar to random forests, gradient boosting models select important features while building trees by prioritizing features that reduce error the most.
4. Practical Considerations for Choosing a Feature Selection Method
Selecting the right feature selection method is crucial for achieving optimal results. Several factors should be considered when making this decision.
4.1. Dataset Size
- Small Datasets: For small datasets, wrapper methods may be feasible, as the computational cost is less of a concern. However, be mindful of overfitting.
- Large Datasets: For large datasets, filter methods are often preferred due to their computational efficiency. Embedded methods can also be a good choice.
4.2. Number of Features
- Low-Dimensional Data: If the dataset already has a small number of features, feature selection may not be necessary.
- High-Dimensional Data: Feature selection is particularly important for high-dimensional datasets, where it can significantly reduce complexity and improve performance.
4.3. Model Type
- Linear Models: L1 regularization (Lasso) is a good choice for linear models, as it encourages sparsity and selects the most relevant features.
- Tree-Based Models: Decision trees, random forests, and gradient boosting algorithms have built-in feature selection capabilities.
- Other Models: Wrapper methods can be used with any model type, but they may be computationally expensive.
4.4. Feature Interactions
- No Interactions: If there are no significant interactions between features, filter methods may be sufficient.
- Complex Interactions: Wrapper and embedded methods are better at capturing complex feature interactions.
4.5. Computational Resources
- Limited Resources: Filter methods are the most computationally efficient and are suitable for resource-constrained environments.
- Sufficient Resources: Wrapper and embedded methods can be used if sufficient computational resources are available.
4.6. Interpretability Requirements
- High Interpretability: Filter methods and feature selection techniques that retain the original features are preferred when interpretability is crucial.
- Lower Interpretability: Dimensionality reduction techniques that create new, artificial features may be acceptable if interpretability is less of a concern.
4.7. Understanding the Data
Before applying any feature selection method, it’s essential to have a good understanding of the data. This includes:
- Data Types: Identifying the types of features (e.g., numerical, categorical, text).
- Missing Values: Handling missing values appropriately.
- Outliers: Detecting and addressing outliers.
- Domain Knowledge: Leveraging domain expertise to identify potentially relevant features.
4.8. Iterative Approach
Feature selection is often an iterative process. It may be necessary to experiment with different methods and parameters to find the optimal feature subset for a particular problem.
5. Step-by-Step Guide to Implementing Feature Selection
Implementing feature selection involves a series of steps, from data preparation to model evaluation. Here’s a comprehensive guide to help you through the process:
5.1. Data Preparation
- Data Cleaning: Handle missing values, outliers, and inconsistencies in the data.
- Data Transformation: Transform features into a suitable format for the chosen feature selection method. This may involve scaling numerical features, encoding categorical features, or normalizing text data.
- Feature Engineering: Create new features based on existing ones to capture potentially important relationships or patterns.
- Data Splitting: Divide the data into training, validation, and test sets. The training set is used to train the model, the validation set is used to evaluate the performance of different feature subsets, and the test set is used to assess the final model’s performance on unseen data.
5.2. Feature Selection Method Selection
- Consider the factors: Choose a feature selection method based on the factors discussed earlier, such as dataset size, number of features, model type, and computational resources.
- Experiment with different methods: It may be necessary to experiment with different methods to find the optimal one for a particular problem.
5.3. Feature Selection Implementation
- Apply the chosen method: Implement the selected feature selection method using a programming language like Python and libraries like scikit-learn.
- Tune parameters: Adjust the parameters of the feature selection method to optimize its performance.
- Select the feature subset: Choose the feature subset that yields the best performance on the validation set.
5.4. Model Training
- Train the model: Train the chosen machine learning model using the selected feature subset and the training data.
- Tune hyperparameters: Optimize the model’s hyperparameters using the validation set.
5.5. Model Evaluation
- Evaluate the model: Assess the model’s performance on the test set using appropriate evaluation metrics.
- Compare with baseline: Compare the model’s performance with a baseline model trained on all features or a random subset of features.
- Iterate if necessary: If the model’s performance is not satisfactory, iterate on the feature selection and model training steps.
5.6. Deployment and Monitoring
- Deploy the model: Deploy the trained model to a production environment.
- Monitor performance: Continuously monitor the model’s performance and retrain it as needed to maintain its accuracy.
6. Tools and Libraries for Feature Selection in Python
Python offers a rich ecosystem of libraries for implementing feature selection techniques. Here are some of the most popular and useful ones:
6.1. Scikit-learn
Scikit-learn is a comprehensive machine learning library that provides implementations of various feature selection methods, including:
- Filter Methods:
VarianceThreshold,SelectKBest,SelectPercentile,SelectFpr,SelectFdr,SelectFromModel - Wrapper Methods:
RFE,RFECV - Embedded Methods: L1 regularization in
LogisticRegressionandLinearSVC, feature importance inDecisionTreeClassifierandRandomForestClassifier
6.2. Statsmodels
Statsmodels is a library that provides tools for statistical modeling, including feature selection techniques like:
- Forward Selection: Implemented using stepwise regression.
- Backward Elimination: Implemented using stepwise regression.
6.3. Featurewiz
Featurewiz is a fast and efficient feature selection library that uses a combination of techniques to identify the most relevant features.
6.4. BorutaPy
BorutaPy is a feature selection library based on the Boruta algorithm, which uses random forest to identify important features.
6.5. mlxtend
Mlxtend (machine learning extensions) is a library that provides a variety of useful tools for machine learning, including feature selection techniques like:
- Sequential Feature Selector: Implements forward selection and backward elimination.
6.6. Selecting the Right Library
The choice of library depends on the specific feature selection methods you want to use and your familiarity with the library. Scikit-learn is a good starting point, as it provides a wide range of methods and is well-documented.
7. Real-World Applications of Feature Selection
Feature selection plays a crucial role in a wide array of real-world applications, enhancing the accuracy, efficiency, and interpretability of machine learning models.
7.1. Healthcare
- Disease Diagnosis: Identifying key symptoms and medical tests that are most predictive of a particular disease. This helps doctors make more accurate diagnoses and develop personalized treatment plans.
- Drug Discovery: Selecting the most promising drug candidates based on their chemical properties and biological activity. This accelerates the drug discovery process and reduces the cost of clinical trials.
- Predictive Modeling: Predicting patient outcomes based on their medical history, lifestyle factors, and genetic information. This enables healthcare providers to identify patients at risk and implement preventive measures.
7.2. Finance
- Credit Risk Assessment: Identifying the most important factors that determine a borrower’s creditworthiness. This helps lenders make more informed decisions about loan approvals and interest rates.
- Fraud Detection: Detecting fraudulent transactions by identifying suspicious patterns and anomalies in financial data.
- Algorithmic Trading: Selecting the most relevant market indicators and technical analysis tools for predicting stock prices and making trading decisions.
7.3. Marketing
- Customer Segmentation: Identifying the most important characteristics that define different customer segments. This allows marketers to tailor their campaigns and messaging to specific groups of customers.
- Targeted Advertising: Selecting the most relevant factors for predicting which customers are most likely to respond to a particular ad. This improves the effectiveness of advertising campaigns and reduces wasted ad spend.
- Churn Prediction: Predicting which customers are most likely to churn (stop using a product or service). This enables businesses to take proactive steps to retain those customers.
7.4. Natural Language Processing (NLP)
- Text Classification: Selecting the most informative words and phrases for classifying text documents into different categories (e.g., spam vs. non-spam, positive vs. negative sentiment).
- Sentiment Analysis: Identifying the most relevant features for determining the sentiment (positive, negative, or neutral) expressed in a piece of text.
- Machine Translation: Selecting the most important words and phrases for translating text from one language to another.
7.5. Computer Vision
- Image Recognition: Identifying the most relevant features for recognizing objects in images.
- Object Detection: Selecting the most important features for detecting the presence and location of objects in images.
- Image Segmentation: Identifying the most relevant features for segmenting images into different regions.
7.6. Manufacturing
- Quality Control: Identifying the most important factors that affect product quality. This helps manufacturers optimize their processes and reduce defects.
- Predictive Maintenance: Predicting when equipment is likely to fail based on sensor data and historical maintenance records. This enables manufacturers to schedule maintenance proactively and avoid costly downtime.
8. Addressing Common Challenges in Feature Selection
While feature selection offers numerous benefits, it also presents certain challenges that need to be addressed carefully.
8.1. Overfitting
- Challenge: Wrapper methods, in particular, can be prone to overfitting if the model is too complex or the validation set is not representative of the population.
- Solution: Use cross-validation to evaluate the performance of different feature subsets. Simplify the model by reducing the number of features or using regularization techniques.
8.2. Feature Dependencies
- Challenge: Filter methods treat each feature in isolation, ignoring potential interactions or dependencies between features.
- Solution: Use wrapper or embedded methods that can capture feature dependencies. Consider feature engineering to create new features that capture interactions between existing features.
8.3. Non-Linear Relationships
- Challenge: Some feature selection methods assume linear relationships between features and the target variable.
- Solution: Use non-linear feature selection methods or transform the features to make the relationships more linear.
8.4. Unstable Feature Selection
- Challenge: The selected feature subset may vary significantly depending on the training data or the specific feature selection method used.
- Solution: Use ensemble feature selection methods that combine the results of multiple feature selection techniques. Use cross-validation to assess the stability of the selected feature subset.
8.5. Computational Cost
- Challenge: Wrapper methods can be computationally expensive, especially for large datasets.
- Solution: Use filter methods or embedded methods for large datasets. Consider using parallel computing to speed up the feature selection process.
8.6. Data Leakage
- Challenge: Data leakage occurs when information from the test set is used to train the model. This can lead to overly optimistic performance estimates.
- Solution: Ensure that feature selection is performed only on the training data. Do not use the test data to select features or tune hyperparameters.
8.7. Curse of Dimensionality
- Challenge: As the number of features increases, the amount of data required to train a reliable model grows exponentially.
- Solution: Use feature selection to reduce the dimensionality of the data. Consider dimensionality reduction techniques like PCA.
9. Feature Selection Best Practices
To ensure successful feature selection and maximize its benefits, follow these best practices:
9.1. Start with a Clear Goal
- Define the objective: Clearly define the goal of feature selection. Are you trying to improve accuracy, reduce complexity, or enhance interpretability?
- Identify the target variable: Clearly identify the target variable you are trying to predict.
9.2. Understand the Data
- Explore the data: Thoroughly explore the data to understand its characteristics, including data types, missing values, outliers, and relationships between features.
- Leverage domain knowledge: Use domain expertise to identify potentially relevant features and guide the feature selection process.
9.3. Choose the Right Method
- Consider the factors: Choose a feature selection method based on the factors discussed earlier, such as dataset size, number of features, model type, and computational resources.
- Experiment with different methods: It may be necessary to experiment with different methods to find the optimal one for a particular problem.
9.4. Validate the Results
- Use cross-validation: Use cross-validation to evaluate the performance of different feature subsets.
- Compare with baseline: Compare the model’s performance with a baseline model trained on all features or a random subset of features.
9.5. Document the Process
- Keep a record: Document the feature selection process, including the methods used, the parameters tuned, and the results obtained.
- Explain the rationale: Explain the rationale behind the chosen feature subset.
9.6. Iterate and Refine
- Be prepared to iterate: Feature selection is often an iterative process. Be prepared to experiment with different methods and parameters to find the optimal feature subset for a particular problem.
- Refine the process: Continuously refine the feature selection process based on the results obtained.
9.7. Avoid Data Leakage
- Be vigilant: Ensure that feature selection is performed only on the training data. Do not use the test data to select features or tune hyperparameters.
9.8. Consider Feature Engineering
- Create new features: Consider creating new features based on existing ones to capture potentially important relationships or patterns.
- Transform existing features: Transform existing features to make the relationships with the target variable more linear or to improve the performance of the feature selection method.
9.9. Balance Performance and Interpretability
- Strive for balance: Strive for a balance between model performance and interpretability. A highly accurate model that is difficult to understand may not be as valuable as a slightly less accurate model that is easier to explain.
9.10. Keep it Simple
- Avoid overcomplicating: Avoid overcomplicating the feature selection process. Start with simple methods and gradually increase complexity as needed.
10. The Future of Feature Selection
The field of feature selection is constantly evolving, driven by the increasing complexity of data and the growing demand for more accurate and interpretable machine learning models. Here are some of the emerging trends and future directions:
10.1. Automated Feature Engineering
- Trend: Automated feature engineering (AutoFE) is a technique that automatically generates new features from existing ones. This can help to identify potentially important features that might be missed by manual feature engineering.
- Impact: AutoFE can significantly improve model performance and reduce the time and effort required for feature engineering.
10.2. Deep Learning for Feature Selection
- Trend: Deep learning models can be used for feature selection by learning representations of the data that are optimized for a particular task.
- Impact: Deep learning-based feature selection can be particularly effective for high-dimensional data and complex relationships.
10.3. Explainable AI (XAI)
- Trend: Explainable AI (XAI) aims to make machine learning models more transparent and interpretable. Feature selection plays a crucial role in XAI by identifying the most important features that drive the model’s predictions.
- Impact: XAI can increase trust in machine learning models and enable stakeholders to understand and validate their decisions.
10.4. Feature Selection for Streaming Data
- Trend: Feature selection for streaming data is a challenging problem that requires techniques that can adapt to changing data distributions and identify relevant features in real-time.
- Impact: Feature selection for streaming data can enable real-time decision-making in applications like fraud detection and predictive maintenance.
10.5. Meta-Learning for Feature Selection
- Trend: Meta-learning is a technique that learns how to learn. It can be used to automatically select the most appropriate feature selection method for a given dataset.
- Impact: Meta-learning can automate the feature selection process and improve its effectiveness.
FAQ: Frequently Asked Questions About Feature Selection
1. What is the difference between feature selection and feature extraction?
Feature selection selects a subset of existing features, while feature extraction transforms the original features into a new set of features.
2. When should I use feature selection?
Use feature selection when you have a large number of features, some of which may be irrelevant or redundant.
3. What are the different types of feature selection methods?
The main types of feature selection methods are filter methods, wrapper methods, and embedded methods.
4. How do I choose the right feature selection method?
Consider factors like dataset size, number of features, model type, and computational resources.
5. Can feature selection improve model performance?
Yes, feature selection can improve model performance by reducing overfitting and improving generalization.
6. Is feature selection always necessary?
No, feature selection is not always necessary. If you have a small number of features that are all relevant, feature selection may not be needed.
7. How do I avoid overfitting during feature selection?
Use cross-validation to evaluate the performance of different feature subsets.
8. What is the curse of dimensionality?
The curse of dimensionality refers to the challenges that arise when working with high-dimensional data.
9. Can feature selection improve model interpretability?
Yes, feature selection can improve model interpretability by reducing the number of features that need to be considered.
10. What are some common tools for feature selection in Python?
Some common tools for feature selection in Python include scikit-learn, statsmodels, and featurewiz.
Feature selection is a powerful tool for building more effective and efficient machine learning models. By understanding the different methods and techniques, and by following best practices, you can unlock the full potential of your data and achieve better results. At LEARNS.EDU.VN, we are dedicated to providing you with the knowledge and resources you need to master feature selection and other essential machine learning skills.
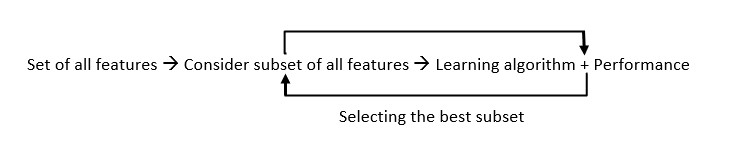 Feature Selection Process
Feature Selection Process
Unlock Your Machine Learning Potential with LEARNS.EDU.VN
Are you ready to take your machine learning skills to the next level? At LEARNS.EDU.VN, we offer a comprehensive range of courses and resources to help you master feature selection and other essential techniques. Whether you’re a beginner or an experienced data scientist, we have something to offer. Explore our extensive library of articles, tutorials, and hands-on projects. Join our community of learners and connect with experts in the field. Don’t miss out on the opportunity to enhance your skills and advance your career. Visit LEARNS.EDU.VN today and start your journey towards machine learning mastery.
Contact Us:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: LEARNS.EDU.VN
Start your learning journey with learns.edu.vn and unlock your full potential in the world of machine learning. Master feature engineering, dimensionality reduction, and variable selection to build powerful and insightful models.
