Supervised machine learning is a foundational concept in artificial intelligence (AI) and a core element of many real-world applications. This comprehensive guide will delve into the intricacies of supervised learning, explaining its workings, types, algorithms, advantages, disadvantages, and practical uses.
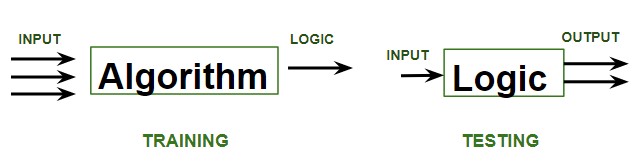
The image above illustrates the core of supervised learning: a model is trained on a labeled dataset (training phase) and then used to predict outcomes for new, unseen data (testing phase).
How Supervised Machine Learning Works
Supervised learning operates on the principle of learning from labeled data. Each data point in the training dataset is paired with a corresponding label or target variable, representing the correct output. The algorithm analyzes this data, identifying patterns and relationships between the input features and the output labels. This process allows the model to learn a mapping function that can predict the output for new, unseen inputs.
The learning process involves iteratively adjusting the model’s internal parameters to minimize the difference between its predictions and the actual labels. This adjustment often utilizes optimization techniques like gradient descent. Once trained, the model’s performance is evaluated using a separate test dataset to ensure it generalizes well to new data. Techniques like cross-validation help refine the model further, balancing bias and variance for optimal prediction accuracy.
Types of Supervised Learning
Supervised learning encompasses two primary problem types:
- Classification: Predicts categorical outputs, assigning input data to predefined categories or classes. Examples include spam detection (spam or not spam) and image recognition (identifying objects in images).
- Regression: Predicts continuous outputs, estimating numerical values based on input features. Examples include predicting house prices based on size and location or forecasting stock prices based on market trends.
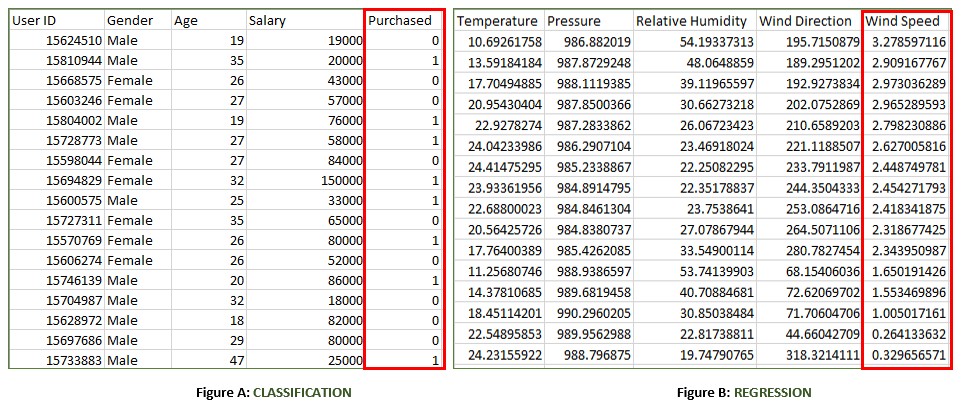
The image above shows examples of labeled datasets for both classification (Figure A: predicting purchase behavior) and regression (Figure B: predicting wind speed). Typically, data is split 80/20 for training and testing.
Supervised Learning Algorithms
A variety of algorithms power supervised learning, each with unique strengths and weaknesses. Here’s a table summarizing some prominent ones:
| Algorithm | Type(s) | Purpose | Method | Use Cases |
|---|---|---|---|---|
| Linear Regression | Regression | Predict continuous values | Linear equation minimizing sum of squares of residuals | Predicting continuous values |
| Logistic Regression | Classification | Predict binary outcomes | Logistic function transforming linear relationship | Binary classification tasks |
| Decision Trees | Both | Model decisions and outcomes | Tree-like structure with decisions and outcomes | Classification and Regression tasks |
| Random Forests | Both | Improve prediction accuracy | Combining multiple decision trees | Reducing overfitting, improving prediction accuracy |
| SVM | Both | Classify or predict continuous values using hyperplanes | Maximizing margin between classes | Classification and Regression tasks |
| KNN | Both | Predict based on nearest neighbors | Finding k closest neighbors | Sensitive to noisy data |
| Gradient Boosting | Both | Combine weak learners into a strong model | Iteratively correcting errors | Improve prediction accuracy |
| Naive Bayes | Classification | Predict class based on feature independence assumption | Bayes’ theorem | Text classification, spam filtering, sentiment analysis |
Training a Supervised Learning Model: Key Steps
Training a successful supervised learning model involves a systematic process:
- Data Collection and Preprocessing: Gathering, cleaning, and preparing the labeled data.
- Splitting the Data: Dividing the data into training and testing sets.
- Choosing the Model: Selecting the appropriate algorithm for the task.
- Training the Model: Feeding the training data to the algorithm.
- Evaluating the Model: Assessing performance on the test set using metrics like accuracy, precision, and recall.
- Hyperparameter Tuning: Optimizing model settings for improved performance.
- Final Model Selection and Testing: Choosing the best model and validating its performance.
- Model Deployment: Implementing the model for real-world use.
Advantages and Disadvantages of Supervised Learning
Advantages:
- High accuracy in prediction.
- Clear performance evaluation metrics.
- Ability to solve complex tasks.
Disadvantages:
- Requires large amounts of labeled data.
- Prone to overfitting if not carefully managed.
- Can be computationally expensive for complex models.
- Sensitive to bias in training data.
Conclusion
Supervised learning is a powerful tool for building predictive models. Its ability to learn from labeled data and generalize to new instances fuels a wide range of applications, including image recognition, natural language processing, spam filtering, and medical diagnosis. While challenges like data requirements and overfitting exist, careful model selection, training, and evaluation can mitigate these issues, unlocking the full potential of supervised learning.
