Deep learning, a powerful subset of machine learning, can be both supervised and unsupervised, depending on the task and the data available, and at LEARNS.EDU.VN, we aim to simplify these complex concepts for everyone. Deep learning algorithms learn from vast amounts of data to make predictions or decisions, and understanding whether they are supervised or unsupervised is crucial to harnessing their potential. Enhance your AI acumen by exploring the nuances of deep learning paradigms with us.
1. What Is Deep Learning and How Does It Work?
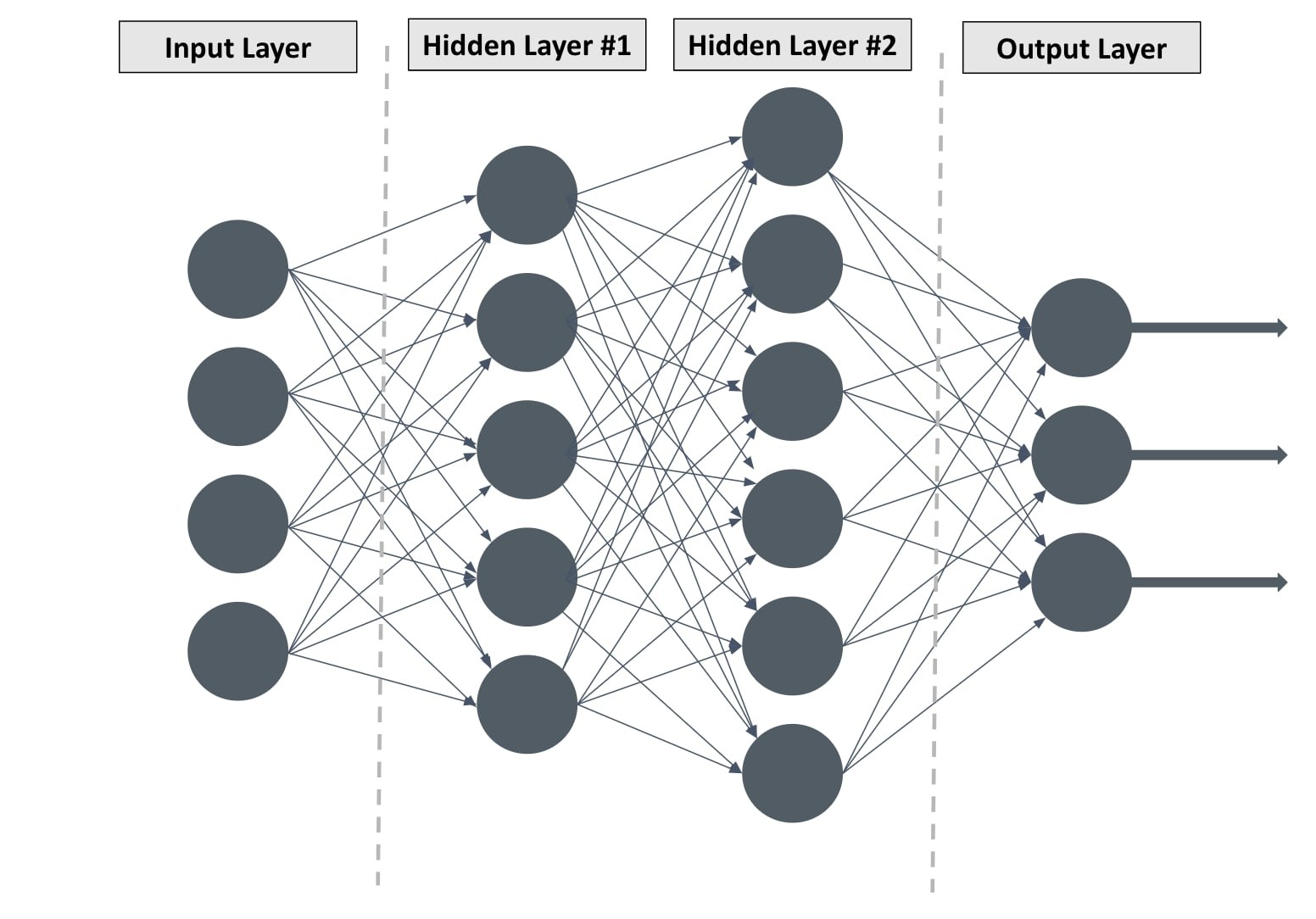
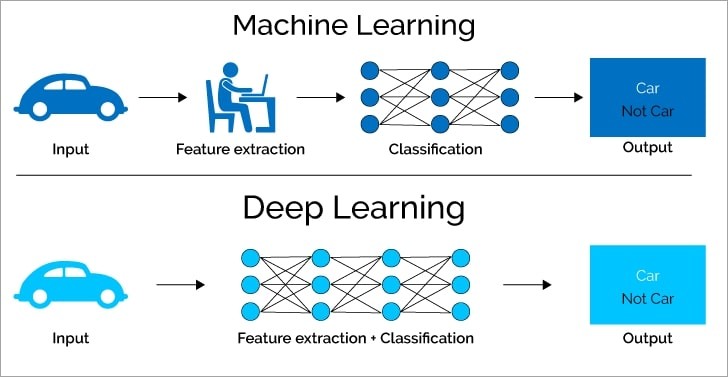
Deep learning is a subfield of machine learning that uses artificial neural networks with multiple layers (hence, “deep”) to analyze data and make predictions. These networks are inspired by the structure and function of the human brain, allowing them to learn complex patterns from large datasets.
- Artificial Neural Networks (ANNs): ANNs are the core of deep learning, composed of interconnected nodes (neurons) organized in layers. Each connection between neurons has a weight, and the network learns by adjusting these weights based on the input data.
- Multiple Layers: Deep learning networks have multiple hidden layers between the input and output layers. These layers enable the network to learn hierarchical representations of the data, with each layer extracting more abstract features.
- Learning Process: Deep learning models learn through a process called backpropagation, where the network adjusts its weights to minimize the difference between its predictions and the actual values in the training data.
2. Supervised Learning in Deep Learning Explained
In supervised learning, deep learning models are trained on labeled data, meaning each input is paired with a corresponding correct output. The model learns to map inputs to outputs by minimizing the error between its predictions and the true labels.
- How It Works: Supervised deep learning involves feeding the model labeled data, allowing it to learn the relationship between inputs and outputs. The model adjusts its parameters to minimize a loss function, which measures the error between its predictions and the true labels.
- Common Algorithms:
- Convolutional Neural Networks (CNNs): Ideal for image recognition tasks, CNNs learn spatial hierarchies of features from images.
- Recurrent Neural Networks (RNNs): Well-suited for sequential data, such as text or time series, RNNs have feedback connections that allow them to maintain a memory of past inputs.
- Deep Neural Networks (DNNs): General-purpose neural networks with multiple layers, DNNs can be used for a wide range of supervised learning tasks.
- Use Cases:
- Image Classification: Identifying objects in images (e.g., cats, dogs, cars).
- Object Detection: Locating and classifying objects within an image.
- Natural Language Processing (NLP): Sentiment analysis, machine translation, and text classification.
- Speech Recognition: Converting spoken language into text.
3. Unsupervised Learning in Deep Learning Explained
In unsupervised learning, deep learning models are trained on unlabeled data, meaning there are no predefined outputs. The model learns to discover hidden patterns, structures, or relationships in the data without any explicit guidance.
- How It Works: Unsupervised deep learning involves feeding the model unlabeled data, allowing it to learn the underlying structure of the data. The model adjusts its parameters to optimize an objective function, which measures the quality of the discovered patterns.
- Common Algorithms:
- Autoencoders: Learn to encode and decode data, typically used for dimensionality reduction or feature learning.
- Generative Adversarial Networks (GANs): Generate new data samples that resemble the training data, often used for image synthesis or data augmentation.
- Restricted Boltzmann Machines (RBMs): Learn a probability distribution over the input data, used for feature learning and dimensionality reduction.
- Use Cases:
- Clustering: Grouping similar data points together.
- Anomaly Detection: Identifying rare or unusual data points.
- Dimensionality Reduction: Reducing the number of variables in a dataset while preserving its essential structure.
- Feature Learning: Automatically discovering useful features from the data.
- Generative Modeling: Creating new data samples that resemble the training data.
4. Key Differences Between Supervised and Unsupervised Deep Learning
Understanding the key differences between supervised and unsupervised deep learning is essential for choosing the right approach for a given task.
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data | Labeled data with input-output pairs | Unlabeled data without predefined outputs |
| Goal | Learn a mapping from inputs to outputs | Discover hidden patterns or structures in the data |
| Algorithms | CNNs, RNNs, DNNs | Autoencoders, GANs, RBMs |
| Evaluation | Measured by accuracy, precision, recall, F1-score, etc. | Measured by clustering metrics, reconstruction error, etc. |
| Human Guidance | Requires labeled data and predefined outputs | Requires less human intervention |
| Use Cases | Classification, regression, prediction | Clustering, anomaly detection, dimensionality reduction |
5. Semi-Supervised Learning: A Hybrid Approach
Semi-supervised learning combines elements of both supervised and unsupervised learning. It involves training a model on a dataset that contains both labeled and unlabeled data.
- How It Works: Semi-supervised learning leverages the labeled data to guide the learning process, while also using the unlabeled data to discover additional patterns or structures in the data.
- Benefits:
- Improved accuracy compared to unsupervised learning.
- Reduced need for large amounts of labeled data compared to supervised learning.
- Use Cases:
- Image classification with limited labeled data.
- Medical diagnosis where obtaining labeled data is expensive.
- Natural language processing with a mix of labeled and unlabeled text.
6. Reinforcement Learning: Learning Through Interaction
Reinforcement learning is a type of machine learning where an agent learns to make decisions in an environment to maximize a reward. While it’s distinct from supervised and unsupervised learning, it shares some characteristics with both.
- How It Works: Reinforcement learning involves an agent interacting with an environment, taking actions, and receiving rewards or penalties based on the outcomes. The agent learns to optimize its actions to maximize the cumulative reward over time.
- Key Components:
- Agent: The learner that makes decisions.
- Environment: The world in which the agent operates.
- Actions: The choices the agent can make.
- Rewards: The feedback the agent receives based on its actions.
- Policy: The strategy the agent uses to select actions.
- Use Cases:
- Game Playing: Training agents to play games like chess or Go.
- Robotics: Controlling robots to perform tasks in the real world.
- Autonomous Driving: Developing self-driving cars.
- Resource Management: Optimizing resource allocation in various systems.
7. Applications of Deep Learning in Various Industries
Deep learning has revolutionized many industries by enabling new capabilities and improving existing processes.
- Healthcare:
- Medical Imaging: Diagnosing diseases from X-rays, MRIs, and CT scans.
According to research by Stanford University, deep learning models can detect certain types of cancer with accuracy comparable to that of human radiologists. - Drug Discovery: Identifying potential drug candidates and predicting their effectiveness.
- Personalized Medicine: Tailoring treatments to individual patients based on their genetic information.
- Medical Imaging: Diagnosing diseases from X-rays, MRIs, and CT scans.
- Finance:
- Fraud Detection: Identifying fraudulent transactions in real-time.
- Algorithmic Trading: Developing automated trading strategies.
- Risk Management: Assessing and managing financial risks.
- Credit Scoring: According to a 2023 report by Experian, deep learning models can improve the accuracy of credit scoring by up to 20% compared to traditional methods.
- Retail:
- Recommendation Systems: Recommending products to customers based on their preferences.
- Customer Segmentation: Grouping customers into segments based on their behavior.
- Supply Chain Optimization: Optimizing inventory levels and logistics.
- Personalized Shopping: Retailers have been leveraging AI algorithms to provide personalized shopping experiences. According to McKinsey, retailers using AI-driven personalization have seen a 5-10% increase in sales.
- Manufacturing:
- Quality Control: Detecting defects in manufactured products.
- Predictive Maintenance: Predicting when equipment is likely to fail.
- Process Optimization: Optimizing manufacturing processes to improve efficiency.
- Automotive:
- Autonomous Driving: Developing self-driving cars.
- Advanced Driver-Assistance Systems (ADAS): Providing features such as lane departure warning and automatic emergency braking.
- Predictive Maintenance: Monitoring vehicle health and predicting maintenance needs.
8. How to Choose Between Supervised and Unsupervised Deep Learning
Choosing between supervised and unsupervised deep learning depends on the nature of the problem and the available data.
- Considerations:
- Availability of Labeled Data: If you have labeled data, supervised learning is a natural choice. If you don’t, unsupervised learning is the way to go.
- Task Goals: If you want to make predictions or classifications, supervised learning is appropriate. If you want to discover hidden patterns or structures in the data, unsupervised learning is better.
- Data Complexity: If the data is complex and high-dimensional, deep learning may be necessary to extract meaningful features.
9. Advantages and Disadvantages of Deep Learning Approaches
Deep learning offers several advantages over traditional machine learning techniques, but also comes with some drawbacks.
| Approach | Advantages | Disadvantages |
|---|---|---|
| Supervised | High accuracy, ability to make predictions and classifications, well-suited for many real-world tasks | Requires labeled data, can be prone to overfitting, may not be suitable for discovering hidden patterns |
| Unsupervised | Ability to discover hidden patterns and structures in data, does not require labeled data, useful for exploratory data analysis | Lower accuracy compared to supervised learning, may be difficult to interpret results, requires careful selection of algorithms and parameters |
| Semi-Supervised | Leverages both labeled and unlabeled data, improved accuracy compared to unsupervised learning, reduced need for large amounts of labeled data | Can be more complex to implement, requires careful selection of algorithms and parameters, may not always outperform supervised learning |
| Reinforcement | Ability to learn through interaction, well-suited for decision-making tasks, can achieve superhuman performance in certain domains | Can be difficult to train, requires careful design of the reward function, can be computationally expensive, may not be suitable for tasks with sparse rewards |
10. The Future of Deep Learning and Its Impact
Deep learning is a rapidly evolving field with immense potential to transform many aspects of our lives.
- Emerging Trends:
- Explainable AI (XAI): Developing techniques to make deep learning models more transparent and interpretable.
- Federated Learning: Training models on decentralized data sources without sharing the data itself.
- Self-Supervised Learning: Learning from unlabeled data by creating artificial labels.
- Neuromorphic Computing: Developing hardware that mimics the structure and function of the human brain.
- Potential Impact:
- Healthcare: Revolutionizing medical diagnosis, drug discovery, and personalized medicine.
- Transportation: Enabling autonomous driving and improving traffic management.
- Manufacturing: Optimizing production processes and improving quality control.
- Education: Personalizing learning experiences and providing adaptive tutoring.
11. Supervised Deep Learning: A Detailed Look
Supervised deep learning is like having a teacher who guides the learning process by providing correct answers. This method is perfect when you have labeled data and want to predict specific outcomes.
- How It Works:
- Data Preparation: Gather and label your data. Each piece of data should have a corresponding correct answer.
- Model Selection: Choose a suitable deep learning model, such as a Convolutional Neural Network (CNN) for images or a Recurrent Neural Network (RNN) for text.
- Training: Feed the labeled data into the model and let it learn the relationship between inputs and outputs. The model adjusts its parameters to minimize the difference between its predictions and the true labels.
- Evaluation: Test the model with new, unseen data to assess its performance.
- Benefits:
- High Accuracy: Supervised learning models can achieve high accuracy when trained on large, well-labeled datasets.
- Clear Objectives: The learning process is guided by clear objectives, making it easier to evaluate and improve the model.
- Wide Applicability: Supervised learning is applicable to a wide range of tasks, including image classification, natural language processing, and predictive modeling.
- Limitations:
- Requires Labeled Data: The need for labeled data can be a significant limitation, as labeling data can be time-consuming and expensive.
- Overfitting: Supervised learning models can be prone to overfitting, especially when trained on small datasets. Overfitting occurs when the model learns the training data too well, and fails to generalize to new data.
- Lack of Creativity: Supervised learning models are limited by the data they are trained on, and cannot generate new or creative outputs.
12. Unsupervised Deep Learning: Uncovering Hidden Patterns
Unsupervised deep learning is like exploring a vast, unknown territory without a map. This method is ideal when you have unlabeled data and want to discover hidden patterns or structures.
- How It Works:
- Data Preparation: Gather your data. No labels are needed.
- Model Selection: Choose a suitable unsupervised deep learning model, such as an Autoencoder for dimensionality reduction or a Generative Adversarial Network (GAN) for generating new data.
- Training: Feed the unlabeled data into the model and let it learn the underlying structure of the data. The model adjusts its parameters to optimize an objective function, such as minimizing the reconstruction error or maximizing the similarity between generated data and real data.
- Evaluation: Evaluate the model by assessing the quality of the discovered patterns or structures.
- Benefits:
- No Labeled Data Required: Unsupervised learning does not require labeled data, making it applicable to a wide range of datasets.
- Discovery of Hidden Patterns: Unsupervised learning can uncover hidden patterns or structures in data that would be difficult to find using traditional methods.
- Data Exploration: Unsupervised learning is useful for exploratory data analysis, helping to gain insights into the data and generate new hypotheses.
- Limitations:
- Lower Accuracy: Unsupervised learning models typically achieve lower accuracy compared to supervised learning models.
- Difficult to Interpret: The results of unsupervised learning can be difficult to interpret, requiring careful analysis and domain expertise.
- Requires Careful Selection of Algorithms and Parameters: Unsupervised learning requires careful selection of algorithms and parameters, as different algorithms and parameters can lead to different results.
13. Real-World Examples of Supervised and Unsupervised Deep Learning
To better understand the practical applications of supervised and unsupervised deep learning, let’s look at some real-world examples.
| Application | Type | Description |
|---|---|---|
| Image Classification | Supervised | Identifying objects in images (e.g., cats, dogs, cars). |
| Fraud Detection | Supervised | Identifying fraudulent transactions in real-time. |
| Recommendation Systems | Supervised | Recommending products to customers based on their preferences. |
| Medical Diagnosis | Supervised | Diagnosing diseases from medical images. |
| Anomaly Detection | Unsupervised | Identifying rare or unusual data points in a dataset. |
| Customer Segmentation | Unsupervised | Grouping customers into segments based on their behavior. |
| Dimensionality Reduction | Unsupervised | Reducing the number of variables in a dataset while preserving its essential structure. |
| Generative Modeling | Unsupervised | Creating new data samples that resemble the training data. |
14. Step-by-Step Guide: Building a Supervised Deep Learning Model
Here’s a step-by-step guide to building a supervised deep learning model:
- Gather and Prepare Data: Collect and label your data. Ensure that the data is clean, preprocessed, and split into training and testing sets. Aim for a dataset size of at least 1,000 samples for a simple task, and 10,000+ for more complex tasks.
- Choose a Model: Select a suitable deep learning model based on the task and data type. For image classification, choose a CNN. For text classification, choose an RNN.
- Define the Model Architecture: Define the architecture of the model, including the number of layers, the number of neurons in each layer, and the activation functions.
- Set Hyperparameters: Set the hyperparameters of the model, such as the learning rate, batch size, and number of epochs.
- Train the Model: Train the model on the training data, using an optimization algorithm such as stochastic gradient descent (SGD) or Adam.
- Evaluate the Model: Evaluate the model on the testing data, using metrics such as accuracy, precision, recall, and F1-score.
- Tune the Model: Tune the model by adjusting the architecture, hyperparameters, or training process to improve its performance.
15. Step-by-Step Guide: Building an Unsupervised Deep Learning Model
Here’s a step-by-step guide to building an unsupervised deep learning model:
- Gather and Prepare Data: Collect your data. Ensure that the data is clean and preprocessed.
- Choose a Model: Select a suitable unsupervised deep learning model based on the task and data type. For dimensionality reduction, choose an Autoencoder. For generative modeling, choose a GAN.
- Define the Model Architecture: Define the architecture of the model, including the number of layers, the number of neurons in each layer, and the activation functions.
- Set Hyperparameters: Set the hyperparameters of the model, such as the learning rate, batch size, and number of epochs.
- Train the Model: Train the model on the data, using an optimization algorithm such as stochastic gradient descent (SGD) or Adam.
- Evaluate the Model: Evaluate the model by assessing the quality of the discovered patterns or structures.
- Tune the Model: Tune the model by adjusting the architecture, hyperparameters, or training process to improve its performance.
16. The Role of Data in Deep Learning Success
Data is the lifeblood of deep learning. The more data you have, the better your model will perform. However, the quality of the data is just as important as the quantity.
- Data Quantity: Deep learning models require large amounts of data to learn complex patterns.
- Data Quality: The data should be clean, accurate, and representative of the problem you are trying to solve.
- Data Diversity: The data should be diverse and cover a wide range of scenarios.
- Data Preprocessing: Data preprocessing techniques, such as normalization, standardization, and feature scaling, can improve the performance of deep learning models.
17. Tools and Resources for Deep Learning Enthusiasts
There are many tools and resources available to help you get started with deep learning.
- Deep Learning Frameworks:
- TensorFlow: An open-source deep learning framework developed by Google.
- PyTorch: An open-source deep learning framework developed by Facebook.
- Keras: A high-level API for building and training deep learning models.
- Cloud Computing Platforms:
- Amazon Web Services (AWS): Provides a wide range of cloud computing services, including virtual machines, storage, and databases.
- Google Cloud Platform (GCP): Provides a wide range of cloud computing services, including virtual machines, storage, and databases.
- Microsoft Azure: Provides a wide range of cloud computing services, including virtual machines, storage, and databases.
- Online Courses:
- Coursera: Offers a wide range of online courses on deep learning and related topics.
- edX: Offers a wide range of online courses on deep learning and related topics.
- Udacity: Offers a wide range of online courses on deep learning and related topics.
- Books:
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville.
- “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow” by Aurélien Géron.
- “Python Deep Learning” by Daniel Hulme.
18. Common Challenges and How to Overcome Them
Deep learning is a powerful tool, but it comes with its own set of challenges.
- Overfitting:
- Challenge: The model learns the training data too well, and fails to generalize to new data.
- Solution: Use techniques such as regularization, dropout, and data augmentation.
- Vanishing Gradients:
- Challenge: The gradients become very small during training, preventing the model from learning.
- Solution: Use techniques such as ReLU activation functions, batch normalization, and skip connections.
- Computational Cost:
- Challenge: Training deep learning models can be computationally expensive, requiring powerful hardware and long training times.
- Solution: Use techniques such as transfer learning, distributed training, and cloud computing.
- Lack of Interpretability:
- Challenge: Deep learning models can be difficult to interpret, making it hard to understand why they make certain predictions.
- Solution: Use techniques such as explainable AI (XAI) to make the models more transparent and interpretable.
19. Ethical Considerations in Deep Learning
As deep learning becomes more prevalent, it’s important to consider the ethical implications of its use.
- Bias: Deep learning models can inherit biases from the data they are trained on, leading to unfair or discriminatory outcomes.
- Privacy: Deep learning models can be used to infer sensitive information about individuals, raising privacy concerns.
- Security: Deep learning models can be vulnerable to adversarial attacks, where small changes to the input can cause the model to make incorrect predictions.
- Transparency: Deep learning models can be difficult to interpret, making it hard to understand why they make certain predictions.
20. Deep Learning Trends: What’s Next?
Deep learning is a rapidly evolving field, with new trends and technologies emerging all the time.
- Explainable AI (XAI): Making deep learning models more transparent and interpretable.
- Federated Learning: Training models on decentralized data sources without sharing the data itself.
- Self-Supervised Learning: Learning from unlabeled data by creating artificial labels.
- Neuromorphic Computing: Developing hardware that mimics the structure and function of the human brain.
- Quantum Machine Learning: Combining deep learning with quantum computing to solve complex problems.
Deep learning is a versatile and powerful tool that can be applied to a wide range of problems. Whether it’s supervised, unsupervised, or somewhere in between, understanding the different approaches and their applications is essential for anyone working in the field of AI. By exploring these concepts further at LEARNS.EDU.VN, you’ll be well-equipped to leverage deep learning for your own projects and innovations.
Ready to dive deeper into the world of deep learning? Visit learns.edu.vn today and explore our comprehensive courses and resources designed to help you master this cutting-edge technology. Whether you’re a beginner or an experienced practitioner, we have something for everyone. Contact us at 123 Education Way, Learnville, CA 90210, United States, or reach out via Whatsapp at +1 555-555-1212. Let’s unlock the potential of deep learning together Learn about data science, neural networks, and machine intelligence.
FAQ Section
Q1: Is Deep Learning always supervised?
No, deep learning can be both supervised and unsupervised, depending on the task and the data available. Supervised deep learning uses labeled data, while unsupervised deep learning uses unlabeled data.
Q2: What are the main differences between supervised and unsupervised deep learning?
Supervised deep learning uses labeled data to learn a mapping from inputs to outputs, while unsupervised deep learning uses unlabeled data to discover hidden patterns or structures in the data.
Q3: What is semi-supervised learning in deep learning?
Semi-supervised learning combines elements of both supervised and unsupervised learning, using a dataset that contains both labeled and unlabeled data.
Q4: What are some common applications of supervised deep learning?
Common applications of supervised deep learning include image classification, object detection, natural language processing, and speech recognition.
Q5: What are some common applications of unsupervised deep learning?
Common applications of unsupervised deep learning include clustering, anomaly detection, dimensionality reduction, and feature learning.
Q6: How do I choose between supervised and unsupervised deep learning?
The choice between supervised and unsupervised deep learning depends on the availability of labeled data, the task goals, and the complexity of the data.
Q7: What are the advantages of supervised deep learning?
Advantages of supervised deep learning include high accuracy, the ability to make predictions and classifications, and applicability to many real-world tasks.
Q8: What are the advantages of unsupervised deep learning?
Advantages of unsupervised deep learning include the ability to discover hidden patterns and structures in data, no requirement for labeled data, and usefulness for exploratory data analysis.
Q9: What are some tools and resources for deep learning?
Tools and resources for deep learning include deep learning frameworks such as TensorFlow and PyTorch, cloud computing platforms such as AWS and GCP, and online courses and books.
Q10: What are some ethical considerations in deep learning?
Ethical considerations in deep learning include bias, privacy, security, and transparency.
