Machine learning stands as a transformative field within computer science, empowering computers to learn from data without explicit programming. Among its diverse branches, supervised learning and unsupervised learning are two primary types, each offering unique approaches to problem-solving. This article delves into the core concepts of supervised learning, elucidating its mechanisms, applications, advantages, and limitations, while also contrasting it with unsupervised learning.
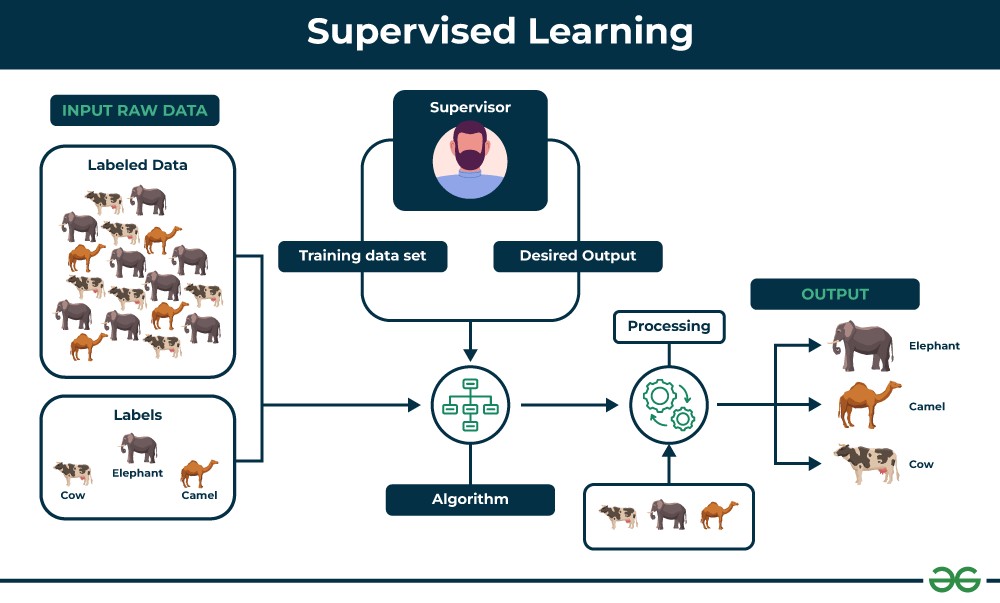
In supervised learning, algorithms are trained using labeled datasets. This means that each data point is tagged with the correct answer or classification, acting as a “supervisor” guiding the learning process. The algorithm’s goal is to learn a mapping function that can predict the output for new, unseen data based on the patterns learned from the labeled training data. This approach is widely used for tasks like classification, regression, and object detection, where the desired outcome is known and can be explicitly taught to the machine.
Unsupervised learning, conversely, operates on unlabeled data. Here, the algorithm explores the data to find inherent patterns and relationships without any pre-defined outputs. It excels in tasks such as clustering, dimensionality reduction, and anomaly detection, where the objective is to discover hidden structures and insights from the data itself.
What is Supervised Learning in Detail?
Supervised learning is fundamentally about learning from examples. Imagine a teacher guiding a student: the teacher provides examples with correct answers, and the student learns to generalize these examples to solve new, similar problems. In supervised learning, the “teacher” is the labeled dataset, and the “student” is the machine learning algorithm.
Labeled data is the cornerstone of supervised learning. It consists of input data paired with corresponding output labels. For instance, in an image classification task, a labeled dataset would contain images of cats and dogs, with each image labeled as either “cat” or “dog”.
The supervised learning algorithm analyzes this labeled data to identify relationships between the input features and the output labels. It aims to build a model that can accurately predict the label for new, unseen input data.
Consider the example of identifying fruits in a basket. To train a supervised learning model, you would provide it with labeled images of different fruits.
 Supervised learning process with fruit basket
Supervised learning process with fruit basket
Key Takeaways of Supervised Learning:
- Learning from Labeled Data: Supervised learning models are trained on datasets where each data point is labeled with the correct output.
- Input-Output Mapping: The algorithm learns the underlying relationship between input features and their corresponding output labels.
- Prediction on New Data: Once trained, the model can predict outputs for new, unlabeled data points based on the learned patterns.
- Teacher-Student Analogy: Supervised learning can be visualized as a machine learning from a “teacher” (labeled data) to solve problems.
Illustrative Example:
Let’s revisit the fruit basket example. Suppose you want to train a machine to identify apples and bananas. You would start by providing the machine with labeled examples:
- Images of apples labeled as “Apple”
- Images of bananas labeled as “Banana”
For each fruit image, the machine analyzes features like shape, color, texture, and size. Through this training process, it learns to associate specific features with each fruit type. For example:
- Rounded shape, red color, and a stem might be associated with “Apple.”
- Elongated, curved shape, and yellow color might be associated with “Banana.”
After training, when you present the machine with a new image of a fruit, it will analyze its features and, based on what it has learned, predict whether it’s an apple or a banana. If the new fruit is a banana, the model should correctly classify it as “Banana” by recognizing its learned features. This demonstrates how supervised learning enables machines to learn from labeled data and apply that knowledge to new, unseen instances.
Types of Supervised Learning Algorithms
Supervised learning algorithms are broadly categorized into two main types, depending on the type of output they predict:
1. Regression
Regression algorithms are used when the desired output is a continuous numerical value. The goal of regression is to model the relationship between input features and a continuous target variable. Examples of regression tasks include:
- Predicting house prices: Based on features like location, size, and number of bedrooms.
- Forecasting stock prices: Based on historical stock data and market indicators.
- Estimating customer churn: Predicting the probability of a customer leaving a service.
Common Regression Algorithms:
- Linear Regression: Models the relationship between variables using a straight line.
- Polynomial Regression: Uses polynomial equations to model non-linear relationships.
- Support Vector Regression (SVR): Employs support vector machines for regression tasks.
- Decision Tree Regression: Uses a tree-like structure to make predictions.
- Random Forest Regression: An ensemble method that combines multiple decision trees.
2. Classification
Classification algorithms are used when the desired output is a categorical value, assigning data points to predefined classes or categories. Classification tasks aim to learn a function that can categorize new data points into the correct class. Examples include:
- Spam email detection: Classifying emails as “spam” or “not spam.”
- Image classification: Categorizing images into objects like “cat,” “dog,” or “car.”
- Medical diagnosis: Classifying patients as having a disease or not based on medical data.
Common Classification Algorithms:
- Logistic Regression: Despite its name, used for binary classification problems.
- Support Vector Machines (SVM): Effective for both linear and non-linear classification.
- Decision Trees: Tree-based models for classification and regression.
- Random Forests: Ensemble of decision trees for improved accuracy.
- Naive Bayes: Based on Bayes’ theorem, often used in text classification.
Evaluating Supervised Learning Models
Evaluating the performance of supervised learning models is crucial to ensure their accuracy and reliability. Different metrics are used for regression and classification tasks.
Evaluation Metrics for Regression
- Mean Squared Error (MSE): Measures the average squared difference between predicted and actual values. Lower MSE indicates better performance.
- Root Mean Squared Error (RMSE): The square root of MSE, provides an interpretable measure of prediction error in the original unit of the target variable. Lower RMSE is better.
- Mean Absolute Error (MAE): Measures the average absolute difference between predicted and actual values. Less sensitive to outliers than MSE and RMSE. Lower MAE is better.
- R-squared (Coefficient of Determination): Represents the proportion of variance in the target variable explained by the model. Higher R-squared (closer to 1) indicates a better fit.
Evaluation Metrics for Classification
- Accuracy: The percentage of correctly classified instances. Higher accuracy is generally better, but can be misleading with imbalanced datasets.
- Precision: The proportion of true positive predictions out of all positive predictions. High precision means fewer false positives.
- Recall: The proportion of true positive predictions out of all actual positive instances. High recall means fewer false negatives.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure of performance, especially useful for imbalanced datasets. Higher F1-score is better.
- Confusion Matrix: A table visualizing the performance of a classification model, showing true positives, true negatives, false positives, and false negatives. Helps understand the types of errors the model is making.
Applications of Supervised Learning
Supervised learning has a vast array of applications across various domains, revolutionizing industries and improving our daily lives:
- Spam Filtering: Supervised learning algorithms effectively classify emails as spam or not spam, protecting users from unwanted and potentially harmful messages.
- Image Classification: From tagging friends in photos to medical image analysis, supervised learning powers systems that automatically categorize images with remarkable accuracy.
- Medical Diagnosis: By analyzing patient data, supervised learning aids in detecting diseases like cancer at early stages, improving treatment outcomes and saving lives.
- Fraud Detection: Financial institutions use supervised learning to identify and prevent fraudulent transactions, safeguarding businesses and customers from financial losses.
- Natural Language Processing (NLP): Supervised learning is fundamental to NLP tasks like sentiment analysis, machine translation, and chatbots, enabling machines to understand and interact with human language.
- Customer Segmentation: Businesses use supervised learning to segment customers based on purchasing behavior and demographics, enabling targeted marketing and personalized customer experiences.
- Predictive Maintenance: In manufacturing and infrastructure, supervised learning predicts equipment failures, allowing for timely maintenance and reducing downtime.
Advantages of Supervised Learning
- Leverages Labeled Data: Supervised learning effectively utilizes labeled data to learn complex patterns and make accurate predictions.
- Optimized Performance: By learning from labeled examples, supervised learning algorithms can achieve high levels of accuracy and performance in specific tasks.
- Solves Real-World Problems: Supervised learning is applicable to a wide range of real-world problems, offering solutions in diverse fields like healthcare, finance, and marketing.
- Classification and Regression Capabilities: Supervised learning handles both classification and regression tasks, providing versatility in problem-solving.
- Result Mapping: It allows for mapping inputs to desired outputs, making it suitable for tasks where the desired outcome is well-defined.
- Control Over Classes: In classification, you have control over defining the classes based on the labeled data.
Disadvantages of Supervised Learning
- Dependency on Labeled Data: Supervised learning requires large, high-quality labeled datasets, which can be expensive and time-consuming to acquire.
- Computationally Intensive: Training complex supervised learning models, especially on large datasets, can be computationally demanding and time-consuming.
- Limited to Known Tasks: Supervised learning models are typically trained for specific tasks and may not generalize well to significantly different or novel situations.
- Complexity with Big Data: Classifying and labeling massive datasets can be a significant challenge for supervised learning.
- Potential for Bias: If the labeled data is biased, the trained model may also exhibit bias in its predictions.
What is Unsupervised Learning?
Unsupervised learning, in contrast to supervised learning, deals with unlabeled data. It’s like exploring uncharted territory without a map. The goal is to discover hidden structures, patterns, and relationships within the data itself, without any predefined categories or labels.
Unsupervised learning algorithms are designed to find inherent groupings (clustering) or reduce the dimensionality of data while preserving essential information.
Alt: Unsupervised learning process depicted with unlabeled images of cats and dogs, showcasing the model grouping them based on similarities without prior labels.
Key Takeaways of Unsupervised Learning:
- Learning from Unlabeled Data: Unsupervised learning models are trained on datasets without predefined labels.
- Pattern Discovery: The algorithm aims to identify hidden patterns, structures, and relationships in the data.
- Data Exploration: Unsupervised learning is valuable for exploring data and gaining insights without prior knowledge of the desired outputs.
- No “Teacher” Guidance: Unlike supervised learning, there is no “teacher” in the form of labeled data to guide the learning process.
Illustrative Example:
Imagine you have a collection of images containing both dogs and cats, but these images are not labeled. Using unsupervised learning, you could aim to group these images based on their visual similarities.
The unsupervised learning algorithm would analyze features like shape, texture, and color in the images and group similar images together. It might identify two distinct groups: one group containing images with pointy ears, fur, and a certain body shape (dogs), and another group with triangular ears, fur, and a different body shape (cats).
Even though the algorithm doesn’t “know” what dogs or cats are beforehand, it can successfully cluster the images based on inherent similarities, effectively separating dogs from cats without any labels.
Types of Unsupervised Learning Algorithms
Unsupervised learning algorithms are primarily categorized into:
1. Clustering
Clustering algorithms group similar data points together based on inherent characteristics. The goal is to partition data into clusters such that data points within a cluster are more similar to each other than to those in other clusters.
Common Clustering Types and Algorithms:
- Hierarchical Clustering: Builds a hierarchy of clusters, either agglomerative (bottom-up) or divisive (top-down).
- K-Means Clustering: Partitions data into k clusters, where each data point belongs to the cluster with the nearest mean (centroid).
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN): Groups together data points that are closely packed together, marking outliers as noise.
- Gaussian Mixture Models (GMMs): Uses Gaussian distributions to model clusters, assuming data points are generated from a mixture of Gaussian distributions.
2. Association Rule Learning
Association rule learning aims to discover interesting relationships or associations between variables in large datasets. It’s often used to find patterns like “people who buy X also tend to buy Y.”
Common Association Rule Learning Algorithms:
- Apriori Algorithm: A classic algorithm for frequent itemset mining and association rule learning.
- Eclat Algorithm: An efficient algorithm for frequent itemset mining using vertical data format.
- FP-Growth Algorithm: Frequent Pattern Growth algorithm, another efficient method for frequent itemset mining without candidate generation.
Evaluating Unsupervised Learning Models
Evaluating unsupervised learning models is more challenging than supervised learning because there are no “correct answers” or labels to compare against. Evaluation often relies on intrinsic measures or domain expertise.
Common Evaluation Metrics for Unsupervised Learning:
- Silhouette Score: Measures how well each data point is clustered, considering both cluster cohesion and separation. Higher scores indicate better clustering.
- Calinski-Harabasz Score: Measures the ratio of between-cluster variance to within-cluster variance. Higher scores indicate better-defined clusters.
- Davies-Bouldin Index: Measures the average similarity ratio of each cluster with its most similar cluster. Lower scores indicate better clustering (less similarity between clusters).
- Adjusted Rand Index (ARI): Measures the similarity between two clusterings, useful when ground truth labels are partially available or for comparing different clustering methods.
- F1-Score (for clustering): Can be adapted for clustering evaluation by considering cluster assignments as “predictions” and using (potentially partially available) labels as “ground truth.”
Applications of Unsupervised Learning
Unsupervised learning is powerful for exploring data and uncovering hidden insights in various applications:
- Anomaly Detection: Identifying unusual patterns or outliers in data, crucial for fraud detection, network security, and system monitoring.
- Scientific Discovery: Uncovering hidden relationships and patterns in scientific data, leading to new hypotheses and breakthroughs in fields like biology and astronomy.
- Recommendation Systems: Grouping users with similar preferences to recommend products, movies, or music, enhancing user experience and driving sales.
- Customer Segmentation: Identifying distinct customer groups based on behavior and characteristics, enabling targeted marketing and personalized services.
- Image Analysis and Computer Vision: Grouping similar images, image compression, and feature extraction for further analysis.
- Dimensionality Reduction: Reducing the number of variables in high-dimensional datasets while preserving essential information, simplifying analysis and improving model performance.
Advantages of Unsupervised Learning
- No Labeled Data Required: Unsupervised learning can work with unlabeled data, making it applicable in situations where labeled data is scarce or expensive to obtain.
- Dimensionality Reduction: Effective for reducing the complexity of high-dimensional data, simplifying analysis and visualization.
- Discovers Unknown Patterns: Unsupervised learning can uncover previously unknown patterns, relationships, and insights hidden within data.
- Insight Generation: Helps gain valuable insights from unlabeled data that might not be apparent through traditional analysis methods.
- Flexibility: Applicable to a wide range of tasks, including clustering, anomaly detection, and dimensionality reduction.
Disadvantages of Unsupervised Learning
- Difficulty in Evaluation: Evaluating the performance of unsupervised learning models can be challenging due to the lack of ground truth labels.
- Lower Accuracy Compared to Supervised Learning: Without labeled guidance, unsupervised learning models may sometimes achieve lower accuracy compared to supervised models in prediction tasks.
- Result Interpretation: Interpreting the results of unsupervised learning, such as cluster assignments, often requires domain expertise and manual labeling.
- Sensitivity to Data Quality: Unsupervised learning can be sensitive to noise, outliers, and missing values in the data, potentially affecting the quality of results.
- Computational Cost: Some unsupervised learning algorithms, especially for clustering large datasets, can be computationally intensive.
Supervised vs. Unsupervised Machine Learning: Key Differences
| Feature | Supervised Machine Learning | Unsupervised Machine Learning |
|---|---|---|
| Input Data | Labeled data | Unlabeled data |
| Computational Complexity | Simpler methods | Computationally complex |
| Accuracy | Generally high accuracy | Potentially lower accuracy |
| Number of Classes | Known number of classes (in classification) | Unknown number of classes |
| Data Analysis | Offline analysis | Real-time analysis possible |
| Algorithms | Linear Regression, Logistic Regression, SVM, Decision Trees, etc. | K-Means, Hierarchical Clustering, Apriori, etc. |
| Output | Desired output is provided | Desired output is not explicitly given |
| Training Data | Uses training data to infer model | No explicit training data usage |
| Model Complexity | Can be limited for complex models | Can handle larger, complex models |
| Model Testing | Model can be directly tested | Direct testing is challenging |
| Common Names | Classification, Regression | Clustering, Association |
| Example | Spam detection, image classification | Customer segmentation, anomaly detection |
| Supervision | Requires supervision (labeled data) | No supervision needed |
Conclusion
Supervised and unsupervised learning are two fundamental and complementary approaches within machine learning. Supervised learning excels when labeled data is available and the goal is to predict specific outcomes or classify data into known categories. Unsupervised learning, on the other hand, shines when dealing with unlabeled data, aiming to discover hidden patterns and structures, explore data, and gain insights. Understanding the strengths and weaknesses of each approach is crucial for choosing the right technique to tackle various machine learning problems effectively. Both supervised and unsupervised learning continue to drive innovation and solve complex challenges across diverse fields, shaping the future of artificial intelligence.
Frequently Asked Questions (FAQs)
1. What is the primary difference between supervised and unsupervised machine learning?
The key difference lies in the type of data they use for training. Supervised learning uses labeled data, where each data point has a corresponding correct answer or label. Unsupervised learning uses unlabeled data, where the algorithm must find patterns and structures without explicit guidance.
2. What exactly is supervised learning?
Supervised learning is a type of machine learning where algorithms learn from labeled datasets. This labeled data acts as a “supervisor,” guiding the algorithm to learn a mapping function that can predict outputs for new, unseen data based on the patterns learned from the labeled examples.
3. What are some common supervised learning algorithms?
Common supervised learning algorithms include:
- Classification Algorithms: Logistic Regression, Support Vector Machines (SVMs), Decision Trees, Random Forests, Naive Bayes.
- Regression Algorithms: Linear Regression, Polynomial Regression, Support Vector Regression (SVR), Decision Tree Regression, Random Forest Regression.
4. What are some common unsupervised learning algorithms?
Common unsupervised learning algorithms include:
- Clustering Algorithms: K-Means Clustering, Hierarchical Clustering, DBSCAN, Gaussian Mixture Models (GMMs).
- Dimensionality Reduction Algorithms: Principal Component Analysis (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE).
- Association Rule Learning Algorithms: Apriori Algorithm, Eclat Algorithm, FP-Growth Algorithm.
5. What is unsupervised learning in simple terms?
Unsupervised learning is like allowing a machine to explore data and find patterns on its own, without telling it what to look for. It’s used to discover hidden structures, groupings, and relationships in unlabeled data.
6. When should I use supervised learning versus unsupervised learning?
Use supervised learning when you have labeled data and want to predict a specific outcome or classify data into known categories. Use unsupervised learning when you have unlabeled data and want to explore the data, discover hidden patterns, or group similar data points together.
Next Article Supervised and Unsupervised Learning in R Programming